こんにちは。エンジニアの大野です。主にフロントエンド周りを担当しています。
去年の話題にはなりますが、2021年10月にNuxt3のベータ版がリリースされました。

公式のリリーススケジュールでは、このブログを書いている2022年3月にrc版、 そして2022年6月には安定版をリリースする予定となっており、着々とバージョンアップへの準備が進められている雰囲気が伺えます。
弊社にもNuxt2の環境で運用しているプロジェクトがあるのですが、vue3のリリース直前に作成した環境であるため、Composition Api やTypeScriptは別途runtimeやbuildのモジュールを個別に入れたりしており、package.json やnuxt.config.ts の設定周りがやや煩雑になっていました。
Nuxt3ではこのあたりのモジュールが標準搭載されるということもあり、チームとしても移行を前向きに検討したいという話が挙がり、実環境にNuxt3を入れてもろもろ調査してみよう、ということになりました。
今回は、実際にNuxt3をプロジェクトに導入しようとして行ったことを書いていきます。
はい。あくまで導入「しようとした」だけです。

Nuxt3自体もまだ本番環境対応はしてませんので、ご注意ください。
Nuxt3へのアップグレードを検討されている方々の参考にでもなれば幸いです。
プロジェクトのフロントエンド事情
Nuxt3導入予定プロジェクトのバージョン周りは以下のようになっています。
node -v v14.15.4 npm --version 6.14.10 yarn --version 1.22.10
package.jsonのフロントエンド周り
"vue": "^2.6.11", "@vue/composition-api": "^0.6.6", "nuxt": "^2.13.0", "@nuxt/typescript-build": "^1.0.3", "@nuxt/typescript-runtime": "^0.4.10",
@vue/composition-api がいまだ0.x.x 版なあたりにミーハー感が漂ってますね。
ちなみに、@nuxtjs/composition-api という便利なnuxt用モジュールがあることも後から知ったのですが、
リファクタリング作業が面倒だったので現状未対応でした。
当初の導入想定フロー
スプリント(1スプリント = 2week)開始前に、以下のようにざっくりと計画を立てました。
- Nuxt2からの移行用ツールとして公式に用意されている Nuxt Bridge を導入
- 開発環境にて動作確認(yarn dev)
- ステージング環境にて動作確認(yarn build、CIによるデプロイ)
- 既存コードをリファクタし、Nuxt3 に対応させる
結論から言ってしまうと、1スプリントで4の作業まで到達することは出来ませんでした。
本記事にもリファクタ内容などは特に記載していませんので、ご承知おきください。
以下、思い出すだけでも頭が痛くなってくるのですが、実際に導入作業を行った際にハマったポイントなどについて記載していきます。
開発環境が動くまで
影響範囲の大きかったエラーと対処法について、3点ほど書かせていただきます。
500エラーがお出迎え
まずはnodeのバージョンを上げておかないと、yarn install 時にエラーが出て Nuxt Bridge がインストールできません。
そのため、v14.15.4 から、本ブログ執筆時点のLTE版である v16.14.0 にアップグレードしています。
この時点で少々嫌な予感はしていたのですが、その後は公式手順通りに package.json や nuxt.confit.ts 、tsconfig.json などを書き換えていきました。
前述の通り @nuxtjs/composition-api は使用していなかったので、既存コードの書き換えはこの時点では特に発生せず、良かったな、程度に思っていました。
が、書き換えを終えた時点で yarn dev (nuxi dev)を実行してみると…ローカルサーバーは起動こそするけれどもページ自体は500エラーで開かず、という状態。
この後しばらく新しくなったNuxtのエラーページと戦うことになります。
とりあえずは500エラーのログに node-sass の記載があったため、node-sass もモジュールアップデートする必要があるのかな?と思い、npmを見に行ったところ

非推奨モジュールになっていました…
仕方ないのでページに記載されている通り、Dart Sass への移行を合わせて行うことにします。
が、置き換えた後に再度 yarn dev を実行してみるも500エラーは解消されず。
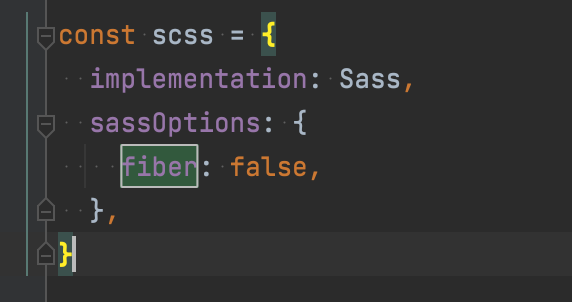
詳細を調べてみると、今度はDart Sassのコンパイル時に使用している fiber というモジュールが node v16 に対応していませんでした。
この時点で、nodeのバージョンを下げるか、コンパイル速度の低下を承知でfiberを切るかの2択を迫られたのですが、コンパイル速度の低下がまだ目に見えるほどではなかったため、後者を採用してnuxt.config.ts 内の設定値を書き換えました。
その後ようやくビルドが通りこそすれど、 Dart Sass に準拠していない記法が警告を大量に出してきたため、個別に未対応モジュールのバージョンUPを行ったり、既存コードのディープセレクタ周りの記法を書き換えたりする作業が発生しました。
configで別ポートを指定しているにも関わらず、開発サーバーが3000番で起動する
nuxt.config.ts の設定で portを指定して localhostを動作させていたのですが、なぜか yarn dev を叩いても docker-compose up を叩いても localhost:3000 しか開けない、という状態でした。
NuxtConfigの型定義を見に行くと
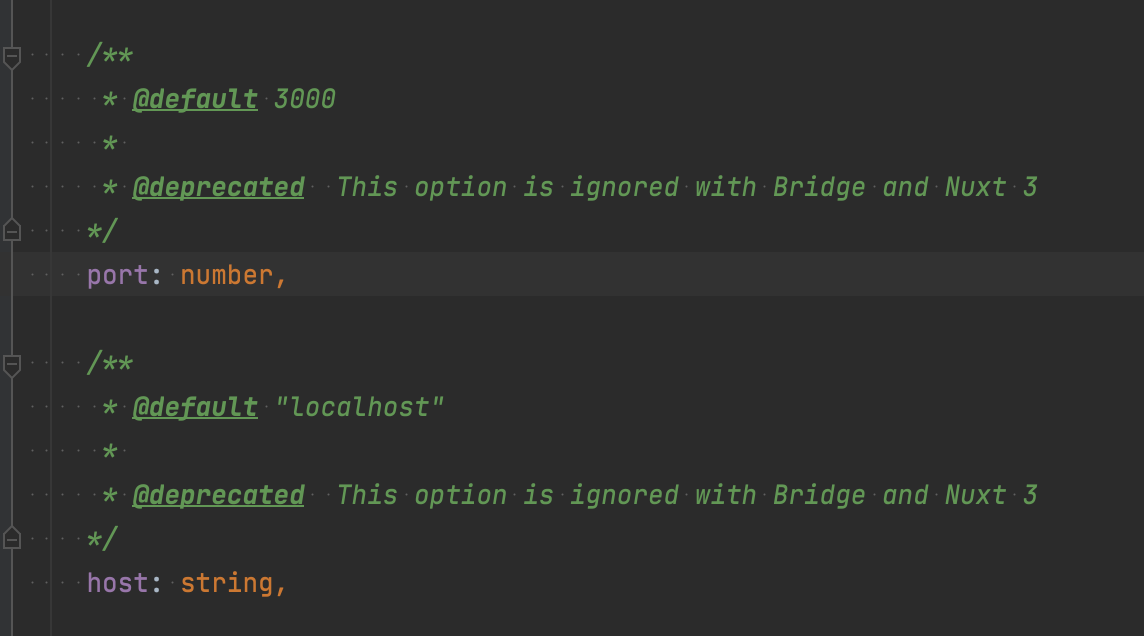
ignoreされるようになったみたいですね。
docker-compose.yml 内で指定するか package.json のコマンドに環境変数として付与するかはちょっと迷ったのですが、最終的には起動コマンドと一緒に渡すように修正しました。
package.json
"dev": "HOST=\"X.X.X.X\" PORT=XXXX nuxi dev",
ホストやポートを指定するため、docker-compose.yml 周りもちょっと確認する必要が出てきたりで、こんなはずではなかった感がほのかに漂ってきています。
src/pages/ に配置したvueファイルを読んでくれない
ルートに置いた app.vue は読み込んでくれるのに src/pages/xxx.vue は読み込んでくれない…という現象でした。
あまり深く追っていないのですが、Nuxt3 では pages ディレクトリがオプション構成に変更されているなどの変更があったので、このあたりのディレクトリ解釈ロジックにも変更が入ったのでしょうか。
以前は srcDir の設定値に src/ を指定していたのですが、
ディレクトリ名がまずいのかな? ということで、上記デフォルト値通りに client/ を指定できるようにディレクトリ構成を変更したところ、想定通りの読み込みをしてくれました。
が、こちらは当初から想定外の大きな変更であり、最終的にはdocker周りのbuildspecやMakefile まで修正しにいく羽目になりました。
ステージング環境が動くまで
上記の様々なエラーを乗り越え、ようやく開発環境が今までと近い形で動くようになったので チームメンバーに動作確認を依頼するため、ステージングデプロイを行ったのです、が。 ここからも割と長めの対応作業に追われることになってしまったので、こちらも3点ほど挙げさせていただきます。
@nuxtjs/fontawesome が使えない
fontawesome-svg-core の export がES6形式に未対応のようでエラーを吐いてました。nuxt.config.ts の transpile にfontawesome関連のモジュールを全て放り込んでも解決せず。
@nuxtjs/fontawesome のモジュール更新頻度が低そうなこともあったため、 fontawesome 使用箇所を全てSVGファイルを読み込む形式に修正して対応しました。モジュール側で何かしらの対応がされると良いのですが…
ちなみにこのエラーが開発環境構築時に出てこなかった理由は、単にfontawesomeの設定をコメントアウトにして開発環境を動かしたからです。 問題の後回しは良くないですね。
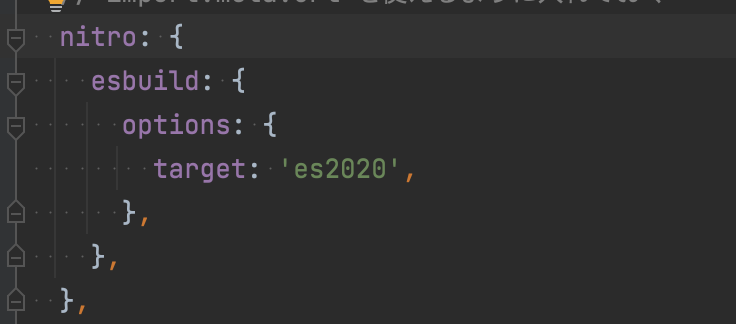
__dirnameが使えなくなるので書き換えたimport.meta.url も使えない
上記使用したファイル読み込み処理があったため、import.meta.url から情報取得してファイル読み込むように書き換えたのですが、import.meta が const import_meta のようにコンパイルされてしまう始末…
以下の設定を nuxt.config.ts に追記し、nitroのビルド設定を変えることで解決しました。
server配下に静的ファイルを配置しても.output(dist)に持っていってくれない
ステージング環境のe2eジョブがこけていたので原因調査したところ、表題にぶち当たりました。
以前は server/api に置いた静的ファイル(JSON)を dist に配置してくれたのですが、NuxtBridgeではimport形式で書かれていない静的ファイルをbuild対象外と判断するようになったみたいです。
jsonファイルを読み込んでいる処理をまるごとimportに置き換えることで解決はしたのですが、既存のコードを追って改修する必要が出たため、こちらも地味に面倒な作業でした。
あとがき
最終的に調査結果としてチームメンバー宛に出したPull Requestは
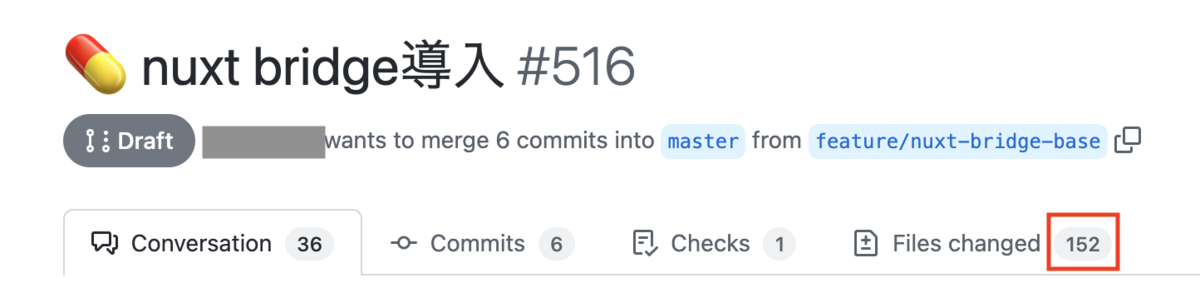
だいぶ気まずい仕上がりとなっていました。
この後にも script setup 記法への変更や inject -> useStateの 置き換え、definePropsの使用などなど…のリファクタリング作業が山程控えており、
まだまだ道のりは長そうなのですが、いつかNuxt3最高、と言える日が来ることを願っております。