こんにちは。フォースタートアップス株式会社でインフラ・SREを担当している吉田です。昨年入社しました。 今回は、インフラ・SRE担当の一人目として入社してからこれまでの約1年間で取り組んできたこと、失敗してきたことや課題をお話します。
入社時の弊社の状況
入社したのは約1年前。当時はオーナーや開発メンバーなど含め社員3〜5人のチームが2つあり、それぞれ別のサービスを開発していました。 社員の他にも、チーム内にはパートナーやインターンの方々もいて、約十名が曜日で入れ替わりながら参加いただいていました。
組織の状況は以下でした。
- 各チーム各サービスとも、開発も進み機能が徐々に増えてきた
- より開発や運用の安定性をより高めていきたい
- サービスレベルの目標設定もしたい
そんな組織の、インフラやSREの担当の一人目としてジョインしました。 入社前は2人チームとお話をもらっていましたが、諸事情で専任の一人目となり、インフラやSREの業務をゼロからスタートすることとなりました。
当時はこの2つのチームを横断して、インフラ関連業務やサービス開発と信頼性の向上に取り組むこととなりました。

入社してから取り組んだこと
直近の活動方針を決める
同じ業務をするメンバーもおらず、右も左もわからない状態からのスタートだったので、
- まずは、メンバーとサービスを理解しよう
- そこから、今困っていることを探して改善/整備しよう
と、ざっくり活動方針をたてて、以下の直近の活動内容をつくりロードマップをひきはじめました。
上の内容に取り組む中で、良かった点と失敗した点がありました。
アラームやインシデントの対応と棚卸し
着任してから、まずは、
- サービスの開発や運用の状況や構成を知ろう
- 安定性を高めるためにはどこからなにをはじめるか、ポイントを探ろう
- 今サービスの安定をおびやかす事象にどのようなものがあるのか知ろう
という考えのもと、
- サービスを知るには、まずは日々のアラームや障害の対応にガンガン参加することだ!
- チームが今、何を大事にして何を追っているのか、まずはつかむぞ!
という思いで動き出しました。

...というのは半分建前で、実はその裏では「早く馴染みたい、早く役に立ちたい」という焦りや不安がとても大きかったのです。
というのも、各チームは人数が少ないこともあってか、
- チームの方針に則りながらも各メンバーが自律的に積極的に動いている
- 誰かがアサインしなくても開発Issueがどんどん上から解決されていく
- また、サービスの問題もチームで話し合い分析し、Issue化して協力して取り組むことができている
という、自律しながらも協力して取り組む文化のある、統率のとれたチームでした。

このチームとともに活動をしていくためには、
- 自分も早くIssueを取れるようにならないといけない
- 早く各チームのメンバーに、一員として認められたい
- この無力感を脱したい
という焦りを感じていました。

そのためには「四の五の言わず、まずは現状把握と対応だ!🔥」という(勝手な)思いがありました。
失敗:入社直後はなかなか役に立てず空回り
まずは各チーム各サービスのアラームやインシデント対応に参加をはじめます。が、しかし早速つまづきます。
- 発生するアラーム、発生する事象が、日々とても多い
- 発生している事象が、どこの何が起因なのかがつかめない
- サービスを構成するサービスが複数存在し、データストアの相互参照もあり
- 対応を優先するべきアラームなのか、対応が不要なアラームなのかの判断がつかず、勝手に右往左往してしまう
既存のメンバーはそのアラームの過去の発生頻度や様子から、発生箇所の特定やおおよその原因を掴んで進んでいきます。
私はサービスの理解が浅いことも有り、問題の概要がつかめずに対応の初動まで時間がかかってしまいます。その間にまた別のアラームや事象が発生します。
- アラームがなる、とりあえず確認する
- これどこのなんのサービス?影響範囲は?前後の事象と関係がある?
- これはなに?これは見るの?これは見なくていいの?
- と思っていたら、別のアラームが...
入社して数日は素早い対応がなかなかできず、悔しい日々が続きました。

気づきと学び:まずは状況観察とヒアリングが大切
日々発生する事象の対応をしながら、少しずつですがサービスの概要や業務の流れを掴み始めました。
同時に、xxxの情報があったらもっと詳しい調査ができるのではないか、原因不明の事象もxxxのログから追えるのではないか、と、一歩引いた目線でインシデントを振り返る時間もできました。
最前線で対応することはもちろんですが、この小さいチームで「SREとして、対応者や門番の役割をさらに超えてチームと伴走し、よりサービスの信頼性をあげるには今何が必要なのだろうか」を考え始めました。
開発メンバーと同様に対応をはじめるだけでなく、別の観点やアプローチをつくることでチームとしてより早く問題解決ができるのではと感じ始めます。
対応人数が少ないからこそ、発生する事象が多いからこそ「まずは状況を観察し判断すること」、インシデントの対応にも言わばトリアージのようなものが一定は必要であると感じました。


実際複数のアラームやインシデントが同時に発生することは少なくなく、その場ですぐに優先度をつけることを求められる場面がありました。
複数の対応の優先度付けや対応箇所の判断ができるようになるためにも、今この初期のタイミングで観察や事象の整理をしなければいけないと気づきました。
このことから、インシデントの検知アラームや障害の対応と並行して、事象や通知を棚卸しをしながら、優先度付けや原因特定がしやすくなるように、以下に取り組みはじめました。
- アラームや通知は精査をして不要なものは流さないこと
- アラームや通知情報を意味ある情報にすること
- 本当の関係者に通知すること(サービスも事象も多いが人数は少ないため、担当に注力できるようノイズを極力減らす)
- 属人化しないよう、誰が見ても同じように状況を認識して動き出せるようになること
例えば、特定の指標の増減や稼働率低下などのSLOを満たしていない事象を通知する場合においても、少し極端な例ですが、

< 稼働率が下がってきた!やばい!
< 応答速度があがってきた!やばい!
と通知をしても、メンバーは

< 具体的に何が起きてるの?
< サービスのどこがおかしいの?
となり、対応の初動に時間がかかってしまうことが多いです。
なので、そうではなく、例えばですが、
<xx時にxxのエラー発生でユーザにエラー画面が見えている
<xx日からxxのAPIの応答時間が延びている
と通知をすれば、メンバーは、

< xxのAPIだから、影響範囲はxxだね
< xx日ということは,もしかしてxxのリリースがきっかけかも...
と、起きている事象の理解や当てをつけることがしやすくなります。
必要な情報を取捨選択して、プロダクトやアプリケーションの詳細な出来事に落とし込み、事象解決につながる情報にして届けることが大切なのだと、当たり前のことではありますが再認識しました。

とすれば、アラームや通知内容は、目指すサービスレベルをおびやかす(SLO違反)警告となるものにするべきです。
今思えば、後述するサービスレベルや追いかける指標(SLI/SLO)の精査に、より早く着手するべきだったと反省しています。
またSLO違反の際に各自がどのように動き出すべきなのか、関係者同士である程度でも目的や方針などの認識をそろえておくともっとスムーズに動けるはずです。
ロードマップや目下の開発を進めることとのバランスもスコープに入れると、メンバーは動きやすくなりますし、チームの心理的安全性の向上にもつながるのではと思います。
良かったこと:現場だから生まれるコミュニケーション
前述のような失敗はありましたが、一方で入社直後で不慣れなことが多い中でも、アラームやインシデントの対応がきっかけでうまく進み始めたことも多くありました。

入社3日目と4日目に続けてインシデントが起きました。具体的には、Elasticsearchの高負荷やノードのダウンによる遅延やエラー応答が発生したのですが、これがきっかけで入社後すぐにチームのメンバーと仕様の深い話をし始めるきっかけができました。
自分 「ちなみにxxxってどうなってるんですか?」
メンバ「これはxxxとxxxでつかっているんだけど、負荷かかってるんだよねー」
自分 「そしたらxxxの部分を見てみますね、ちなみに普段どうやって確認されていますか?」
また、その会話をきっかけに、
「xxxの実行時間と頻度って変更できるものですか?」
「xxxのパラメータで改善できそうです、サービス影響を相談させてください。」
「xxxの作業するので、夜間作業に立ち会っていただけませんか?」
というように、一緒に作業をするきっかけも作ることができました。
対応者として前線に立つことによって、参加できる会話や見える課題もあるのだなと感じた瞬間でした。
サービスの目標と追いかける指標の策定
入社のタイミングで「各サービスの目標(稼働目標など)を定義したい」という課題があり、こちらにも着手しました。
私が入社前からエラーの発生数や応答時間のメトリクスが作成されており、ダッシュボードでそれらを見るという文化もありました。
この文化にも助けられました。どんな指標を大事にしていたか、何に問題意識をもっていたか、がなんとなく掴めたからです。

一方でメンバーからは、各指標の値はわかるが、サービスがどんな状態なのかわからない、何か良い方法はないかと相談を受けました。
そこで、サービスと構成を調べながら、
- サービスが正常に動いているというのはどんな状態なのか
- サービスが正常ではない状態は、どのように観察/検知できるか
を関係者と話し合い、取り急ぎ第一弾として、その条件からシステムの稼働率(≒ SLI)を定義しました。
定義後はチームで稼働率を追っていけるように、稼働率と関連項目を確認するためのダッシュボードを作成し、情報共有とモニタリングをはじめました。
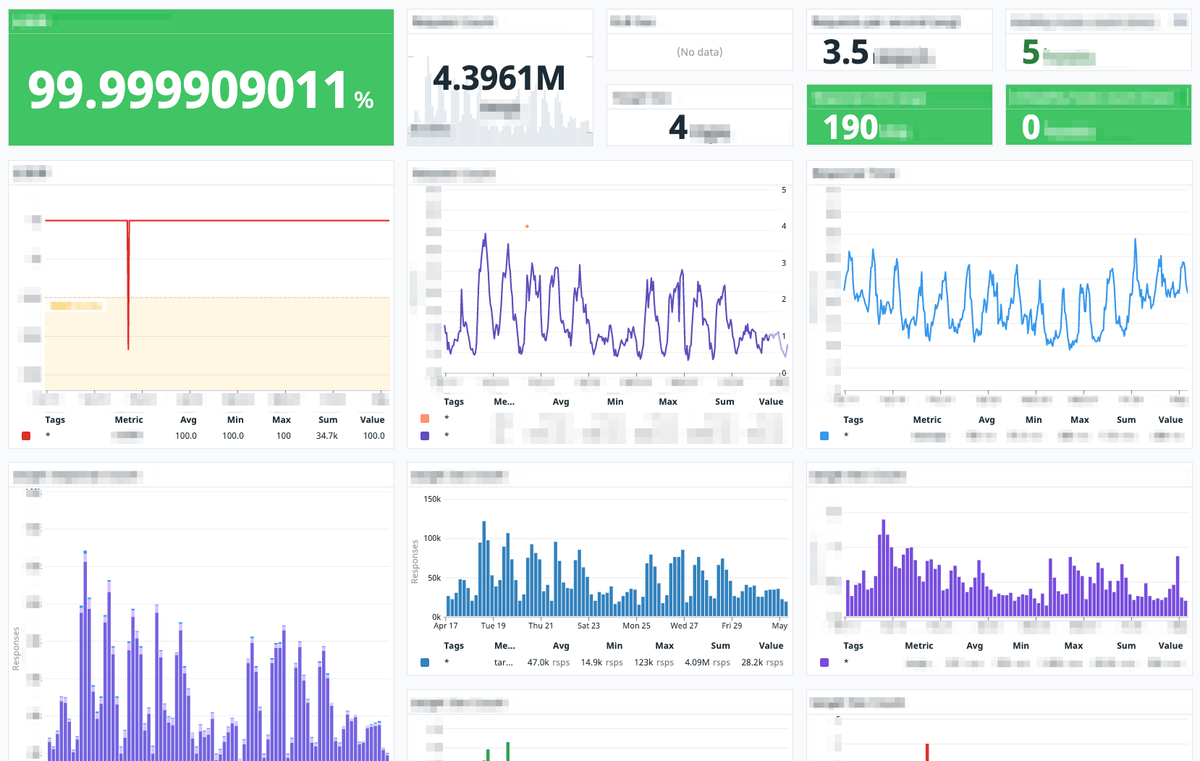

ダッシュボードの表やメトリクスは、指標の数値や推移に加えて、現在目標ライン(≒ SLO)を上回っているのか下回っているのかがぱっと見てわかるように、状態に応じて表示色を変えたりメトリクス内にしきい値を描画したりするなど、まずはわかりやすさを重要視しました。
サービスが正常に動作し価値を届けられているのはどのような状態か、また現在それが目指すレベルにあるのか、チームで共通認識を持ちはじめられたことが良かったです。一方で、見える化したことによる副作用もありました。
良かったこと:サービスの現状理解が進み、稼働に対する意識が高くなった
まずは見える化したことで、以下の気づきや変化がありました。
- 想像以上に未応答数や不安定な時間があることがわかった
- エラーや未応答に意識が向くようになった
既存のダッシュボードでも、その瞬間の応答状況は確認できていましたが、メトリクスで推移を見ることで過去分も確認できるようになりました。
その結果、想像以上に応答率が落ちていたり遅延していたりするタイミングがあることをチームで共有できました。
今では、リリース時の確認や、朝会などでの定期的な確認をするようになり、稼働(サービス提供)への意識もより強くなりました。
失敗したこと:SLO違反との向き合い方の意識合わせ不足
稼働への意識が強くなったことは良かったのですが、現在のサービスとチームでは初めてのSLI・SLOの制定であったこともあり、どうやって運用していくかまでは気がまわっていませんでした。目標値を下回った(SLO違反が発生した)場合のチームの動き方まで、チームと話ができていなかったことが最初の反省点です。
現在のチームが、サービスに対してとても思いが強く責任感のあるチームだったこともあり、そんなチームにとっては「SLOに違反している ≒ 価値が提供できていないユーザがいる」があることはインパクトのあることでした。
そのため、設定当初はメトリクスの上下や一件のエラー発生の通知すべてに反応していました。
一方でサービスの性質上、ユーザーも利用環境も非常に種類が多く攻撃や不正なアクセスも少なくありません。それもあって、見える化をした直後は、認識していなかったエラーも観察されると同時に検知機構も過敏に反応し不要な通知をするなど、粗い部分もありました。
当時はエラーとして検知しても、本当に内部で発生したエラーである場合もあれば、存在しないもしくは許可されていない箇所への不正アクセスである場合もありました。そうすると、対応に疲弊してしまったりアラームや通知がオオカミ少年のように認識されてしまったりすることもありました。
どのエラーが本当に対応しなければいけないもので、どのエラーが誤検知や対応不要なものであるかを、導入の初期段階ではまだ精査しきれてはいませんでした。
エラー検知やSLOの基準となる指標の上下に必要以上に一喜一憂することなく、状況を把握して冷静に対応するためにも、SLOや指標の通知やメトリクスをどのように業務に組み込んでいくのかの認識をあわせることがまずは必要でした。
特にSLOを設定したばかりでチームに馴染むまでは、SLOは何を目的として設定しているのか、満たせている場合はどんな状態で、満たしていない場合はどんな状態で何をしなければいけないのか、を言語化して共通認識を持てるように共有することが必要でした。チームに根付かせるプロセスをもっとしっかり踏まなければいけなかったと反省しています。
失敗したこと:設定後の運用にまで手が回っていないこと
また、指標や目標の見直しまで手が回っていないことも反省点のひとつです。
新しい機能の提供や新しい形式でのコンテンツ配信が増えれば、それぞれに応じて指標や目標ラインも変わるはずです。例えば、APIとHTMLや動画と音声では、それぞれユーザに応答が届くまでの目標時間も異なるはずです。また新しい指標が必要になることもあるはずです。
また、稼働率が低下した要因を追えるようなモニタリングも当時は考慮できていませんでした。例えば内部エラーの検知や発生時のリクエストの詳細情報などです。
SLIやSLOの運用や見える化が、サービスの変化や成長に追いついていませんでした。
特に初回に設定した目標は、しばらくは定期的に確認と検討をする機会を作るべきでした。アップデートを踏まえたサービスの提供価値とそれを満たす状態を見直す機会を設けていきます。
ボトルネックの解消
サービスの状況を見える化した後は、運用やシステムのボトルネックを見つけて解消することに着手しました。
アラームやインシデントの棚卸しと稼働状況の見える化で、性能低下のタイミングや業務コストが高い箇所がつかめたので、その原因やボトルネック箇所の特定の解消、そのためのデータやログの収集や通知に取り組みました。
具体的には以下に取り組みました。
たとえば、特定の時間帯の応答時間の増加をダッシュボードで確認したため調査をはじめたところ、ログやトレース情報からデータ登録時にエラーと数回のリトライの発生を確認しました。参照もそれに引っ張られる形で影響をうけ、アプリケーションの応答速度に影響がでていました。
詳しい内容と原因特定のため、アラームやトレース情報などのモニタリング項目を追加し事象の調査しました。
調査の結果、弊社ではElasticsearchを利用しているのですが、そこでリクエスト過多のエラーが発生していたため、データ更新量やスレッドプールの状態を観察して処理を特定し、データ登録方法やクラスターの設定を見直し、応答速度の増加を解消することができました。
結果的にアラームの見直しやモニタリングが、ボトルネックの発見と解消につながったのは良かったです。
脆弱性の対策
以下のような脆弱性の対策にも着手しました。
1と2については、外部の診断会社や各種サービスを利用して、サーバ/コンテナやアプリケーションに脆弱性がないかスキャンをはじめています。
3については、開発言語やライブラリに関連する脆弱性を、手動でピックアップし調査しています。が、後述しますが、まだうまく運用を回せていません。
4については、クラウドやネットワークに誤った設定(意図しないポート公開やアクセス設定など)がされていないかをチェックしています。
都度確認するのは難しいため、事前にポリシーをつくり、そのポリシーに則っているかをスキャンするようにしています。 このポリシーの作成と運用についてはAWS Config とAWS CDKを用いた手法で取り組んでいます。以下の書籍にまとめていますので、よろしければご覧ください。 https://techbookfest.org/product/5762421668970496?productVariantID=6028076402081792
難しかったこと:活動の必要性や必要なコストの妥当感について理解を得ること
特に2については、診断にかかるコストは安いものではありません。金銭はもちろんですが、環境やデータ準備や診断会社からのヒアリングへの対応もあるため、SREだけでなく開発チームにも負荷はかかります。
1や3のスキャンや情報収集も運用コストがかかります。ユーザに提供価値として直接目に見えて届くものではなく、効果の実感につながるまでに時間も機会も必要です。
意味のある脆弱性対策として機能させるには、継続的な活動と活動を行うための一定のリソースが必要になります。
また、せっかく調査して得た脆弱性情報も、サービスに与える影響に落とし込めないと、情報が流れても誰にも有益な情報としては伝わりません。
「私たち(のサービス)にどう関係あるの?」になるのは当然です。
< xxxでディレクトリトラバーサルの危険あり!
< xxxでオーバーフローの脆弱性が見つかった!
< うちのサービスに関係あるの?
< どのサービスがどう攻撃されるの?
人も工数も少ない小さなチームの中で、継続的な活動にコストを使わせてもらうためには、チームに活動の意義やコストの妥当性が伝わっていることが必要なのだと感じました。
良かったこと:脆弱性に関する書籍の輪読会をおこなったこと
弊社では毎週書籍の輪読会をおこなっているのですが、上の課題に取り組む時期に、輪読会で書籍「体系的に学ぶ 安全なWebアプリケーションの作り方 脆弱性が生まれる原理と対策の実践」を読む機会をつくることができました。
- どんな脆弱性や攻撃手段があるのか
- アプリケーションにどのような影響があるのか
- 対してどのような対策が必要なのか
輪読会でこれらについて学び議論し意見交換をすることができました。
脆弱性の概要や種類を体系的に学ぶことはもちろんですが、自分たちが開発しているサービスではどんな危険性がありどんな対策が必要なのかを、議論しながら深堀りができました。
この輪読会のおかげで、必要性の認識や対策意識について共通認識を作り始めることができました。とてもありがたかったです。
ちなみに、弊社ではビブリオバトルで輪読会の書籍を決めます。ちなみにこの安全なWebアプリケーションの作り方を推薦したのは私です。https://tech.forstartups.com/entry/2022/03/11/110557
課題:スキャン結果の確認と対応のコスト確保
その後、対策の活動をはじめたのですが、スキャン結果をいかしきれず重要度が高くないものは対応が先送りになるケースも少なくありません。
特に実際に4つの脆弱性対策の施策をはじめた直後は、重要度が低いものも含めて大量に検出してしまい、どこから着手すべきかわからなくなるほどでした。
また、3については、開発言語やライブラリに関連する脆弱性を手動でピックアップし調査していました。ですが、どうしても時間がかかってしまうため、今は大きい脆弱性が見つかった場合に個別で調査するにとどまっています。
1と4で、CI/CDへの組み込みや定期スキャンを実施し、2で外部の専門の会社に診断を依頼してカバーしてもらいつつ、緊急性の高いものや詳細な調査が必要なものを3で調査する、という運用にとどまっています。
スキャンをする方法はそろってきたので、スキャン結果取得から対応までに時間が空いてしまわないように、情報の整理と対応を効率的にできるように改善していきます。
利用SaaSの管理
インフラのリソースとあわせて、SaaSやクラウドサービスのアカウントやコストの管理もはじめました。
- メンバー一覧作成(メール・Githubアカウント)
- アカウントの発行と削除
- アカウント発行/削除方法のドキュメント化
- 毎月の請求業務
- プランやアカウント変更の見積もりと稟議申請
- 新しいSaaSを利用するときの確認や申請、法務(リーガルチェック)連携など
開発で多くのSaaSを利用している一方で、各チームにインターンやパートナーの皆さんがいる関係で、不定期にメンバーの増減があります。
アカウント発行が必要なタイミングで、シートが増えてプランも変わり決済が必要となるため、社内の稟議申請も必要になります。
利用しているSaaSをメンバーの情報と一緒に管理をしはじめ、SaaSの利用が必要になったタイミングで必要な権限のアカウントを発行し、費用の増減も合わせて記録・申請する形式で運用をはじめました。
良かったこと:アカウントとコストの管理が一緒にできることの効率性
前述のとおり、メンバーの増減が不定期にあるため、アカウント発行とプランや料金変更も不定期にあります。
都度、チームメンバーが稟議を作成して申請業務をしていては、業務のスイッチングコストも増えてしまいます。担当者が曖昧な状態で、申請や管理業務が漏れていたこともありました。
金額と利用状況をあわせて管理することで、チームで見たときにコミュニケーションや申請業務のコストも抑えられると考えました。
また、不在時に急ぎ必要な場合も、用意した手順書でアカウント発行/削除できる運用にしておくことで、管理人数が少なくとも対応ができるようにしておけば
メンバーが少ない組織でも、各チームを横断して契約や管理ができるようにしておくことで、少しは手間やコストを抑えながら管理できているかなと思っています。
課題:アカウント発行のタイミング
一方で、SaaSのアカウントをいつ発行するか、運用に迷っていることもあります。
- チーム参画時にアカウント一括で発行
- 必要になったタイミングで都度発行
「チーム参画時にアカウントを一括で発行」すれば、アカウント数や費用も見積もりがしやすく、アカウントの登録や削除も利用しているSaaSすべてについて実施するため、ある程度決まった手順で実施ができるため、管理の手間が省けるはずです。アカウント管理のサービスも使いやすいはずです。
一方で業務内容やポジションによって、利用するSaaSに違いもあることから、アカウント発行してもメンバーによっては利用が少ないSaaSもあります。
また、アクティブでないアカウントが気づかずに不正アクセスされるケースもゼロではないと思います。
職種やロールによって、アカウント発行のパターンを作ることも検討しましたが、パターン化することも簡単ではなく、結局必要になったタイミングで追加することになりそうで断念しました。
「必要になったタイミングで都度発行」することで、不正アクセスや使用が少ないアカウント分のコストも抑えることはできますが、アカウント発行の作業は都度不定期に発生しますし、誰に何を発行したか記録しておかないと、全サービスを確認する必要があるためアカウント削除作業の手間が増えます。
現在は、メンバーが多くないことも有り、SaaSの費用削減をねらって「必要になったタイミングで都度発行」の方法をとっています。
誰にどのSaaSアカウント発行をしたか記録する目的も兼ねて、SlackにSaaSアカウント管理の専用のチャンネルを作成して運用しています。

これで、発行依頼や削除依頼にある程度機械的にルールを設けることで手間を減らすことを試みていますが、アカウント周りについてはまだまだ改善しなければいけないことが多いです。
ポストモーテム
これは私がはじめたものではなく前任の方が導入してくれていたのですが、月に一度ポストモーテムの場を設けてチームをまたいでインシデントの振り返りをしています。こちらも入社後に引き継いで継続しています。
専用のリポジトリを用意しており、インシデントの対応が完了した後にリポジトリにPRを作成しフォーマットにそって記録する運用としています。フォーマットはSREの書籍の付録にあるものとほぼ同じです。
月に一度、PRを元に各チームから発表してもらう形式をとっています。
失敗したこと:発表するメンバーの負荷の考慮不足
発表する側の負荷の高さが課題のひとつです。
現在のフローは、以下のようになっており、担当者が自主的に情報をまとめレポートを作る必要があります。
- インシデントの対応完了
- 担当者がポストモーテムのリポジトリにPR作成
- 当時の関係者でPRレビュー
- 月に1度の発表の場でPRのレポートを発表
- PRをマージして完了
ようやく対応が終わってからのインシデントの発表を億劫に感じるメンバーもいたため、日々の業務や運用フローにからめるなどて、もう少し発表者の負担を軽減できないかと運用を見直している最中です。
また、コストはかかるものの、ポストモーテムの場で共有することで自チームにも他チームにも学びがありサービスの向上につながると認識してもらうために、もっと体験を良くできる方法を模索しています。
失敗したこと:議論しやすい場を作り切れていないこと
参加人数が増えたせいか、以前よりも議論や考察の会話の量が減ってきています。
以前は、対応内容について意見の交換があったり、改善のアイデアをライトに言い合ったりする場だったのですが、人数が増えて一人あたりの発言の機会が少なくなったせいか、以前よりも議論の時間が少なくなりました。
また、以前は報告されるインシデントも大小様々で、中にはインシデント発生まで至っていなくとも、ヒヤリハットや運用の学びの出来事が発表されることもありました。
おそらく、議論のネタやアイデアを持ち込むことや、議論そのものに参加することで得られる良い体験や学びの実感が薄くなってきてしまっているのだと思います。
今は全チーム一緒になって開催しているため、一人ひとりの発言の機会を増やすために、報告後の議論をいくつかのグループにわけての実施や、チーム単位での実施も検討しました。ですが、自チームの事象についてそもそも当事者であるためすでに議論がなされていることもあり、他チームとの共有や意見交換も意義の一つであると思い、開催の変更には至っていません。
現在もポストモーテム自体は開催していますが、参加してくれるメンバーが良い体験と感じてもらえるように、議論を促したり質問が気軽にできたりするような場をつくれるように日々やり方や進行を模索しています。
まとめ
課題や失敗は色々ありましたが、総じて「情報を整理して、共通の文脈にあわせた上でチームに共有して、共通の認識をつくっていくこと」をもっと大事にして、「活動’の意義や価値を実感してもらうこと」を増やすべきであっと反省しています。言語化して伝えるだけではなく体験として実感してもらうことが一番伝わると思っています。
チームの設立時からジョインしていたり、同じ立場やロールで動くメンバーがいる場合には、共通言語や共通認識の基礎があるため、それらにずいぶん助けられていたのだと感じました。
複数のスモールチームに参画し、新しいことを始めて運用に取り入れて継続的に活動していくことは、土台づくりからとなるため、時間もかかりとても難しいです。
ですが、各チームの各メンバーがオーナーシップをもってサービス開発に取り組んでおり、良い活動となりそうなことについては積極的に取り入れる文化があることに大きく助けられました。そのおかげで新参者の私が新しいポジションでも活動を続けられています。
「良い活動となりそう」と感じてもらった上で、実際にサービスの価値や信頼性をあげられるように、今後もチームと一緒に議論しながら活動していこうと思います。
これから
現在は、IaCやCI/CDの改善、ログ収集と分析に取り組んでいます。
また今年になって、インフラおよびSRE業務にメンバーが一人増えました。
できることも増え、速度もあげられているのでとてもうれしいです。また何より、各チームと関わりはあったものの、チームとしては一人だったので、楽しさやモチベーションもあがりました。
ですが、まだまだ課題も取り組みたいこともたくさんあります。
フォースタートアップスでは一緒に取り組んでくれる方を募集しています。まだまだ未熟な部分は多いですが、興味を持っていただけましたらぜひご連絡ください。