/assets/images/5108471/original/45120002-b89f-400e-870c-7a9c1b86fde6?1591200935)
はじめに
フォースタートアップスでは展開している各事業の中で、プロダクトや管理ツールなどを開発しています。もちろんインフラ構築から監視、開発に採用する技術選定まで全てチームで議論して採択しています。
自由度があり非常にやりがいのある環境であると感じているのですが、「実際にどんなことをやっているのかよく分からない」というお声をいただくこともあります。本稿においてサービス(プロダクト)と技術視点でフォースタートアップスの取り組みと技術スタックを紹介します。
フォースタに興味のある方や、未来の一緒に働く仲間に読んでいただけると嬉しいです!
フォースタートアップスのご紹介
「for Startups」というビジョンのもと、インターネット/IoTセクターをはじめ、Fintech、リアルビジネス領域も含めた(IT、AI、SaaS、DeepTech、DisruptTech、ドローンテック、MaaS、5G市場など)の転職支援と起業支援を中核とした成長産業支援事業を推進しています。
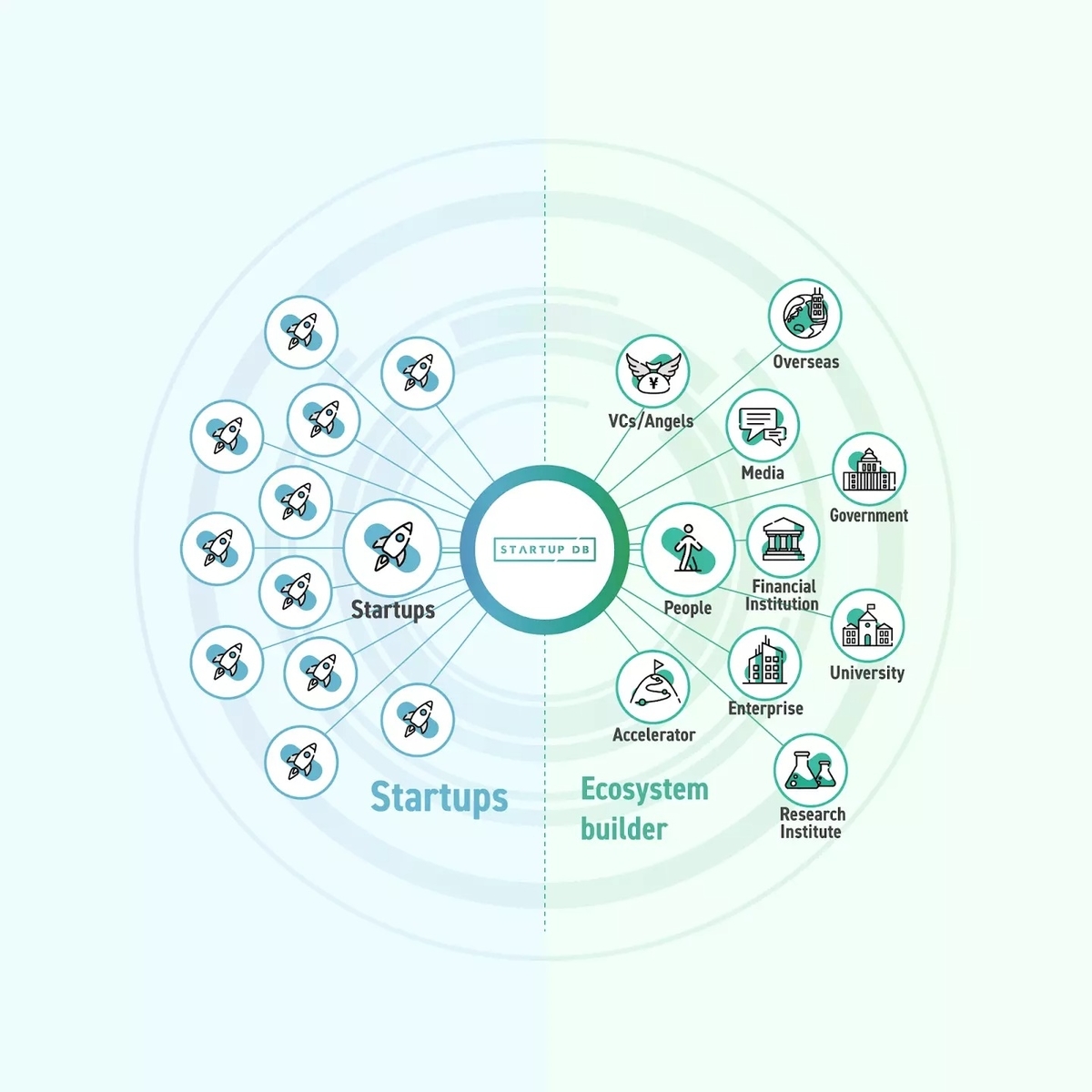
サービスも提供しており、成⻑産業領域に特化した情報プラットフォーム「STARTUP DB(スタートアップデータベース)」(※スタートアップを中心とした15,000社以上の企業情報を掲載)を展開しています。
/assets/images/5107514/original/CHTZh8gVM9kU1myfVHzpFlc5vRVhIyF9demK3dFqkiM9eQ2-mTnuk4lxsQtsjP8kDzItmrTzujCS4iYeiHL79tZ0tgTPEmQ4u5gRXTZTZl95OfMG54Kda8AbLiiO0d9XAwIClgZi?1591182072)
ここからフォースタートアップスで利用されている技術スタックについてご紹介させていただきます。
「サービス」と「技術スタック」のご紹介
1. STARTUP DB

STARTUP DBは、国内最大級の成長産業領域に特化した情報プラットフォームです。
企業データベースは、15,000社を越える日本のベンチャー・スタートアップ企業の情報を保有するとともに、起業家・投資家、エコシステムビルダーの方々累計150名以上のインタビューコンテンツをリリースしています。
また、世界最大級のベンチャー企業データベース「Crunchbase」とデータ連携し、日本企業の情報を海外のプロフェッショナルに届けることで、国内の成長産業領域市場の発展に貢献しています。
企業情報は専任リサーチャー用の管理画面を用意し、毎日情報をキャッチアップして更新していくのに加え、ニュースなどの公開情報を自動収集する技術的チャレンジも行っております。
今後の開発について
2018年にSTARTUP DBは誕生しました。2021年3月に大幅リニューアルを行った新生STARTUP DBがリリースされました。
そして2021年7月にSTARTUP DB ENTERPRISEをリリースし、BtoB SaaSプロダクトとしてグロースフェーズに入っています。
技術スタックとしてはリニューアル時に導入していたNuxt.jsやTypeScriptのおかげで、より開発しやすく、より厳密に、より速く、新しい価値をお届けすることができるようになっています。
IEなどのレガシー環境に対する対応も、LambdaTestとJestを組み合わせた自動テストを用いることで、効率的に行っています。
今後は、STARTUP DBに蓄積された大量のデータとフォースタ全体のスタートアップに関する知識を効果的に用いて、利用者に対しもっと高精度な多くの情報を届けていきます。
技術スタック
■フロントエンド:Nuxt.js / Vue.js / Next.js / React.js / Express / TypeScript
■サーバサイド:Ruby on Rails / TypeScript / Python
■インフラ・開発環境・CI/CD・監視:AWS(ECS・Redis・Aurora MySQL・CloudFront・AWS WAF・Lambda etc.)/ Firebase Authentication / Terraform・Terraform Cloud / Docker / Github Actions / Rollbar / Datadog
■ツール・ドキュメント管理:GitHub / Slack / Zapier / Figma / Notion
2. タレントエージェンシー支援システム(SFA/CRM)

タレントエージェンシー支援システム(SFA/CRM)は、日本を代表するスタートアップと、それを加速させることができるタレント(才気あふれる人々)とのより多くの対話の機会を創出するための「マッチングプラットフォーム」です。
また、ヒューマンキャピタリストの生産性向上を通して、「起業は人のブライトキャリア」というマインドのイノベーションを加速させることを狙いとしています。
※今後の展望に関しては、全てをこちらで語ることはできないので是非カジュアル面談でお話しさせていただけると嬉しいです。
今後の開発について
組織の拡大に伴いこのタレントエージェンシー支援システムがカバーする領域も拡大しており、重要なデータについては集約を進めるとともに、デプロイ頻度を高く保ちつつ安全なリリースが行えるようE2Eテストの導入も行いました。
事業を支えるプロダクトとして更なる機能改善はもちろん、開発において小回りが利くようにバックエンドとフロントエンドの責務分離やIaC管理の改善も行っていきます。
技術スタック
■フロントエンド:Nuxt.js / Vue.js / TypeScript
■サーバサイド:Ruby on Rails / Python
■インフラ・開発環境・CI/CD・監視:AWS(ECS・Lambda・Elasticsearch・Redis・CloudFront・AWS WAF etc.) / Terraform・Terraform Cloud / Docker / Rollbar / Github Actions
■ツール・ドキュメント管理:GitHub / Slack / Zapier / Adobe XD / Notion / Playwright
開発手法・環境

アジャイル
弊社では継続的にアジリティやプロダクトの価値を上げ続けるため、スクラムをベースにアジャイルのプラクティスを組み合わせて開発しています。具体的に現在実施している内容としては、定期的なふりかえり、短いイテレーション、モブプログラミング、カンバン、プランニングポーカーなどです。ただしアジャイルコーチ経験があるメンバーと共に自分たちにとって最適な開発スタイルを探求し続けているため、これは現時点でのスナップショットになります。
その他
ソフトウェアエンジニアは業務の中で学習をし続けることが大切だと思っています。そのため週に1時間の輪読会、週に30分のLT大会の時間を設けています。これまでの輪読会では「プロダクトマネジメント」「Rubyで作るRuby」「UNIXという考え方」「SQLアンチパターン」「入門 監視」などを読んできました。
終わりに
フォースタートアップスのサービスの紹介と技術スタックをまとめてみました。
私たちはビジョンドリブンのチームです。
エンジニアドリブンでもプロダクトドリブンでもありません。
ビジョンを達成するために、どのようなものを作らないといけないか。
そのためにはどのようなエンジニアリングで取り組まないといけないか…という形で落としこんでいくので「技術のみに興味がある」といった志向の方は、少し合わない可能性があります。
ただ、技術的な挑戦がないわけではありません。
ビジョン達成のためには、技術を駆使して解決しなければいけない課題は多く、新しい技術を知らなければいけないので、当然のこととして様々な技術を取り入れています。
もしご興味を持っていただけましたらまずはカジュアルにお話をさせていただきたいです。
We are Hiring!

フォースタートアップスでは共に働く仲間を募集中です。本記事を読んで興味を持っていただけましたら採用情報をご覧ください。