こんにちは.エンジニアの藤井(@yutafujii)です. フォースタではおよそ2年ぶりに”感謝祭”というイベントを開催いたしました.(イベントレポートはこちらでご確認いただけます)
イベント当日は,来場者が受付されるたびに会場内のスクリーンにお名前と写真がポップアップ表示されていました.これは個人開発で作成された簡単なアプリケーションだったのですが,今回はこの開発経緯や技術的検討点についてお話ししようと思います.

感謝祭とは
フォースタ感謝祭とは,日頃お世話になっている起業家や投資家,スタートアップエコシステムに関わるみなさまをオフィスにお招きし,立食パーティ形式で交流していただくイベントです.なお,抗原検査を行った上での参加を必須とするなど,必要な感染対策は講じての実施です.
開催にあたり,今回私は運営委員に入り込み,イベントをよりよいものに仕上げるためにエンジニアリングの視点で関わってきました.
モチベーション
さて,その感謝祭での我々の悩みが,「どうやったらゲスト同士の交流を促進できるか」というものです. 立食パーティという性質上,場だけを提供すると,どうしても知り合い同士で話をしてしまう・知っている人が少なく孤立してしまう,という状況になりがちです.
こうした交流促進の課題感に対して,運営メンバーのキックオフミーティングで一意見として
「会場にスクリーンを設置して,ゲストが来場するごとにそこに顔写真をバーンって映せたら,”あ,いまこの人きたんだ・この人も来ているんだ”ってのがわかって,ゲスト同士がコミュニケーションを取るきっかけが作れるよね」
という提案をしてみたところ.即座に「藤井さん,これできる?」
とアサインされてしまいました.流石,みんな仕事できる.
「うーん,とりあえず検討してみます」
プロトタイプ
個人開発としてプロトタイプ作成に取り掛かります.
当初の要件からすると,スクリーン(=クライアントPC)は受動的に来場者を表示する必要があります.
WebSocketか,定期的なAPIリクエストでのデータ取得のどちらかで実現可能だとは感じ,せっかくなので実装経験がなかったWebSocketを使おうと思いました.その方がリアルタイム性でも勝りますし.
となると,ステートフルなサーバーが必要になるので,S3/CloudFrontでの静的ホスティングではなくEC2かECSに載っけて動かさないといけなさそうです.
ここまでの要件だけなら言語やフレームワークは何でも良さそうだったので,せっかくならと思い実装経験がなかったNext.jsをチョイス.ちなみに弊社では基本的にNuxt.jsを使っています.
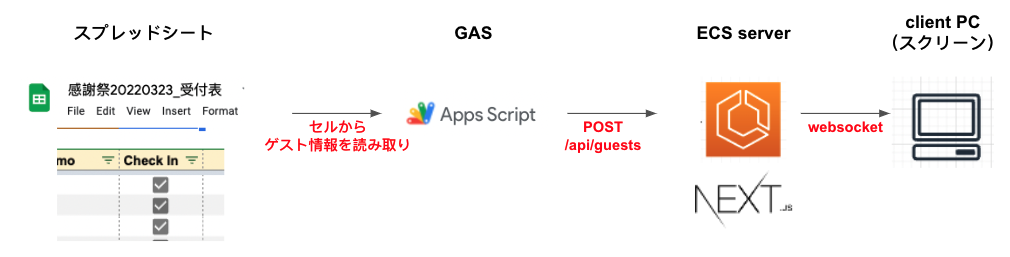
起点となるユーザーの操作ですが,ゲストの受付管理はスプレッドシートで行うのが好ましかったため,以下のようなフローを検討しました:
- 受付で名刺をお預かりし,スプレッドシートにチェックをつける
- GAS(Google App Script)でセルに記載されたゲスト情報をAPIエンドポイントに送信
- リクエストを受け取ったNext.jsサーバーは,WebSocketを通してクライアントに対してデータを送信
- クライアントPCはゲスト情報を画面に表示する
画面への映し方については,ランダムな座標にフェードイン・フェードアウトのアニメーションで表示させました.
できあがったローカルでのプロトタイプはこんな感じです.スプレッドシートにチェックを入れるたびに,画面にゲスト情報が表示されます
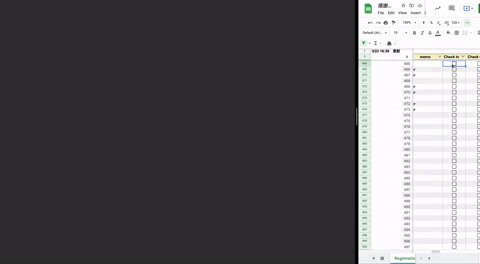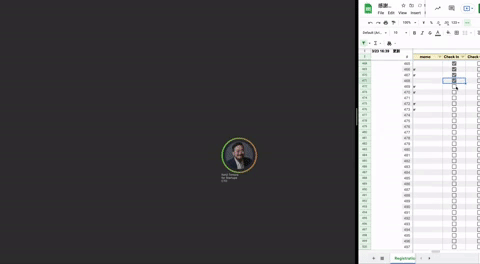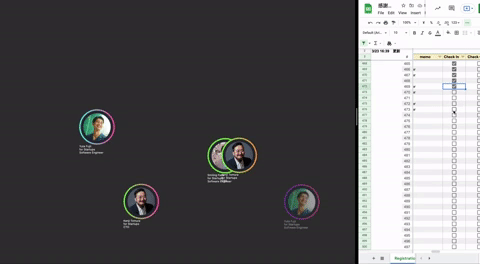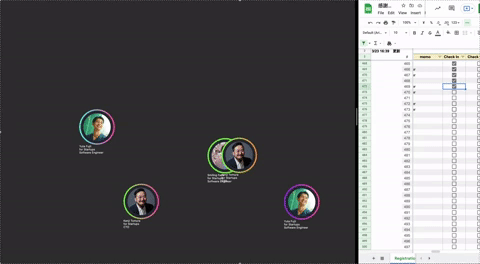
フィードバック
さて,運営チームのミーティングで見せてみました.
「おお〜...」
こういうのってレスポンスからなんとなくわかりますよね.”悪くはなさそうだが,もうちょっと何か”というところですね.
ミーティング中に追加で要件をいくつか整理して時間内に実現可能か試してみることに.
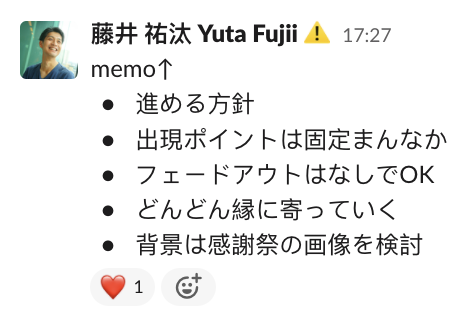
ブラッシュアップ
というわけでこれらに対応していきます
要件1:ゲストのスクリーン出現場所はランダムではなく中央に固定
画面の真ん中にゲスト写真を出現させること自体はもちろん難しくなさそうです.
ただ,一気にゲストが来場して受付担当者がスプレッドシートのチェックボックスを次々に押しても見栄えが悪くならないようにしたい.一瞬で別のゲストの写真に切り替わっちゃったら寂しいですから.
そこで,キューを用いることにしました
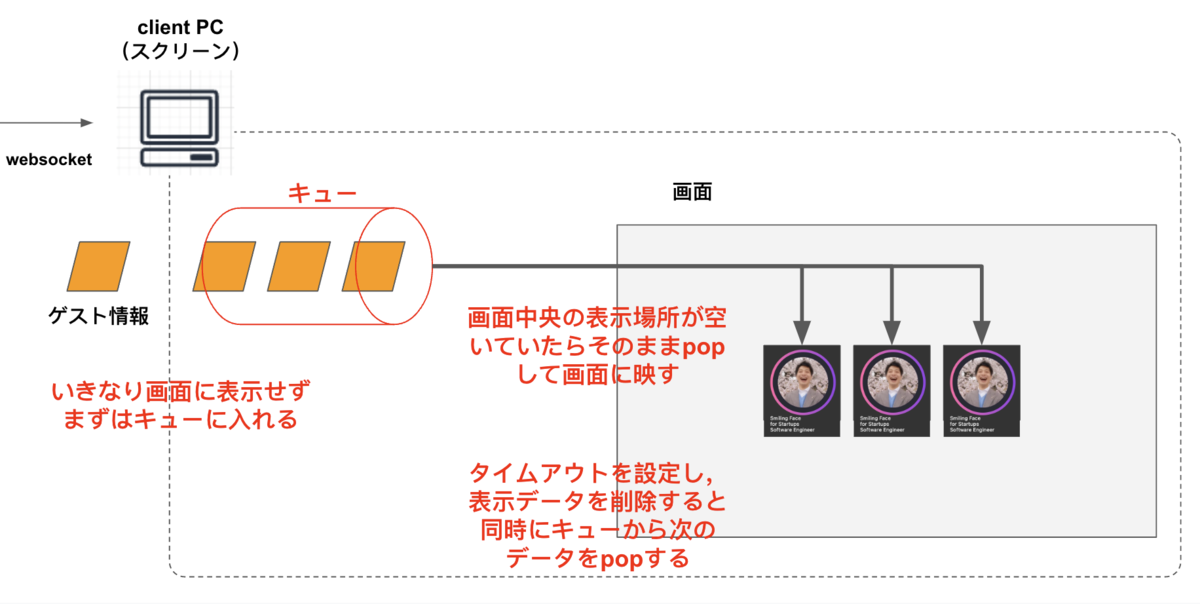
- WebSocketで受理したデータはまずはキューにpush
- 中央の表示部が空いていたらそのままpop
- 表示部では一定時間経過したらデータを落としてキューから次のゲストデータをpopする
こんな感じで実装をしてみます.
// pages/spread.js // *表示パターンごとにページを作り,パターンをコンポーネント名称にした const reducer = (state, action) => { switch (action.type) { case 'ENQUEUE': // 3箇所の表示場所が空いていたら,すぐに表示 // そうでなければキューにpush // 詳細は省略 case 'POP_LEFT': // キューの先頭をpopしてleftに代入 case 'POP_CENTER': // 省略 case 'POP_RIGHT': // 省略 default: return state } } const Spread = () => { // キューとゲストを表示する中央3箇所をステート管理 const [newGuestState, dispatch] = useReducer(reducer, { queue: [], left: undefined, center: undefined, right: undefined, }) // websocket経由でデータを受理したらキューに入れる const socketInitializer = async () => { await fetch('/api/socket') socket = io() socket.on('update-input', msg => { dispatch({ type: 'ENQUEUE', data: JSON.parse(msg) }) }) } useEffect(() => socketInitializer(), []) // 中央3箇所の表示場所はそれぞれデータの変更をウォッチ // 一定時間経過後にキュー先頭をpopして表示する useEffect(() => { if (newGuestState.left) { const timer = setTimeout(() => { dispatch({ type: 'POP_LEFT' }) readyToRender(n) }, TIMEOUT) return () => clearTimeout(timer) } }, [newGuestState.left]) useEffect(() => { // ... }, [newGuestState.center]) useEffect(() => { // ... }, [newGuestState.right]) // ...
要件2:ゲスト写真はフェードアウトせず残し続ける
さて,フェードアウトさせないことはもちろん容易にできそうですが,データの永続性が気になります.
実際のイベント開催時には,何らかの原因で画面が動かなくなってリロードしてみるということが確実に起きると考えていました. その際に画面をリロードしてもこれまで来場されたゲストがきちんと残ってスクリーンに映っているようにするためには,WebSocketでフロー情報を受け取るだけでは実現が難しそうです.ここにきてデータベースが必要そうでした.
そこで,PostgresQLを導入することにしました.ORMにはPrismaを選定しました.はい,公式ドキュメントに載ってたのをそのまま使おうとしただけです.
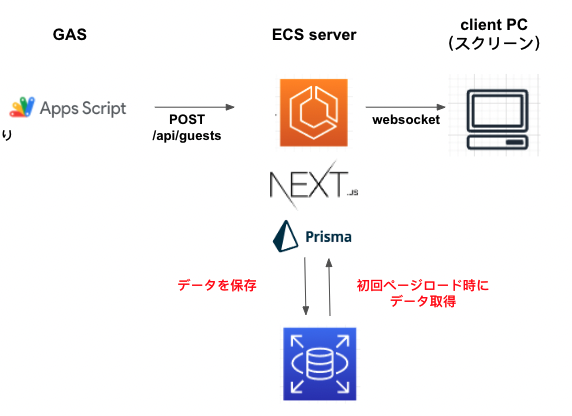
これに伴い,GASからPOSTリクエストを受けるAPIエンドポイントにはデータベースへのINSERT処理を追加し,画面コンポーネントファイルには getServerSideProps を追加しました.
// pages/api/arrive.js const Arrive = catchErrorsFrom(async (req, res) => { if (req.method == 'POST') { try { // APIエンドポイントの処理にデータベース保存を追加 const guest = await prisma.guest.create({ data: { name: req.body.name, company: req.body.company, position: req.body.position, imageUrl: req.body.imageUrl, checked_in_at: new Date().toISOString() } }) res.status(200).json(guest) if (res.socket.server.io) { res.socket.server.io.emit('update-input', JSON.stringify(guest)) } } catch (e) {
// pages/spread.js // ... // 既に来場されたゲスト一覧を取得し最初から表示する const getServerSideProps = async () => { const guests = await prisma.guest.findMany() return { props: { initialGuests: JSON.parse(JSON.stringify(guests)) } } } const Spread = ({ initialGuests }) => { // 来場されたゲストをステート管理 const [guests, setGuests] = useState(initialGuests) const [newGuestState, dispatch] = useReducer(reducer, { queue: [], left: undefined, center: undefined, right: undefined, }) useEffect(() => { if (newGuestState.left) { // 新しく来場されたゲストをguestステートに追加し, const guest = { ...newGuestState.left } const n = guests.length setGuests(prevGuests => [...prevGuests, guest]) const timer = setTimeout(() => { dispatch({ type: 'POP_LEFT' }) // 一定時間経過後に画面周辺に表示させる(メソッド内容は省略) readyToRender(n) }, TIMEOUT) return () => clearTimeout(timer) } }, [newGuestState.left]) // ...
クライアント側の処理はおよそ以下の図のようになります
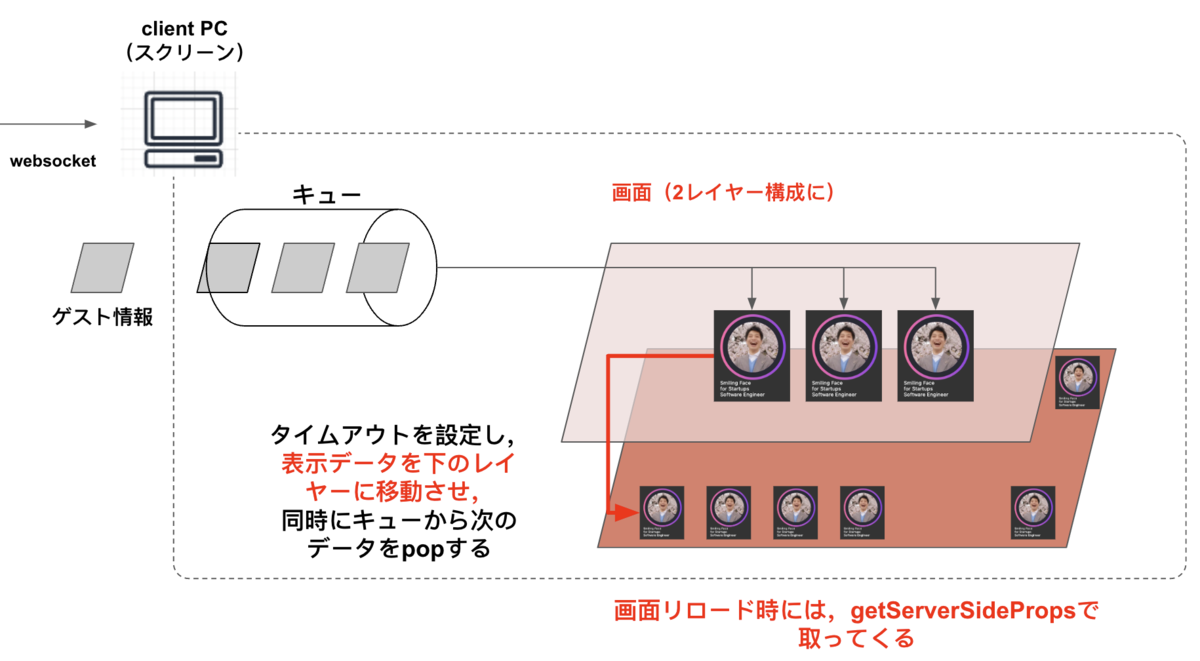
画面の中にゲスト写真をどう配置するのかは次に検討します
要件3:ゲスト写真は来場された順に周辺に寄せて表示していく
要素divにあたるCSSをposition: absolute にしておき,topとleft属性をJS側で与えてあげれば各要素を好きな場所に表示させることはできます.
実際,ランダムな場所に表示させていた最初のプロトタイプはこうして実装していました.
来た人から順に画面の外側に並ぶようにするにはどうしたらいいのか...
まず,ゲスト写真の配置場所としてあり得る座標を計算しておき,中心からの距離が遠い順にソートして,来場された順に先頭の座標から割り当てていく,という方針をとることにしてみました.
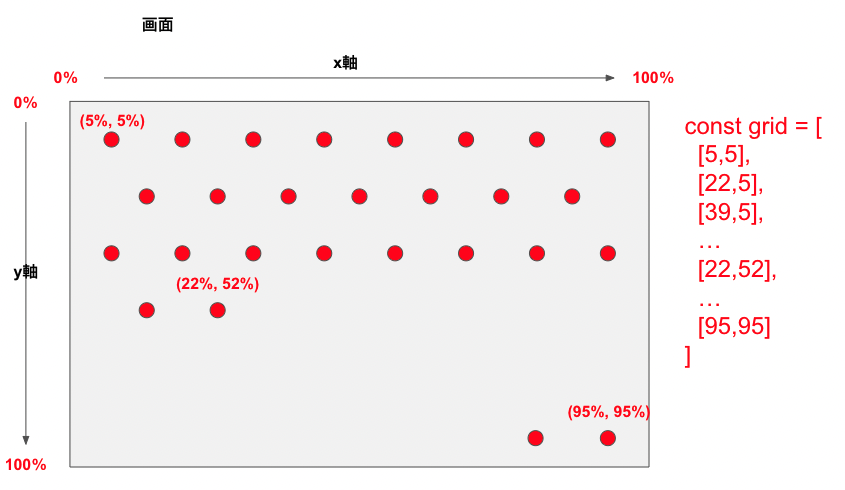
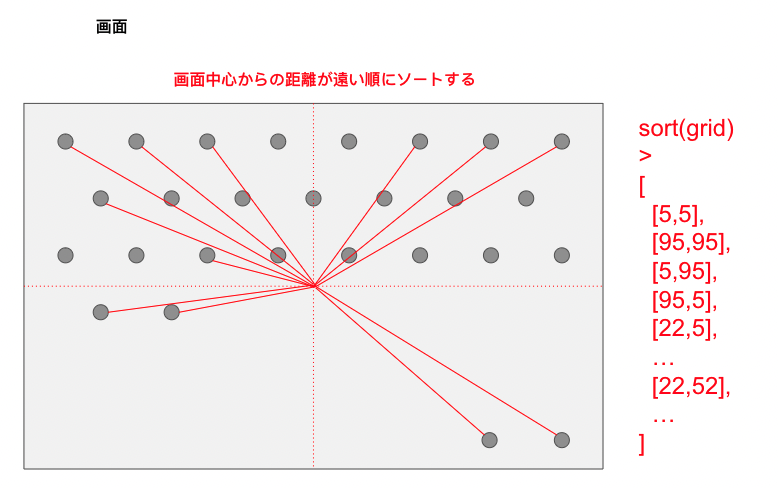
実装としては,座標(grid)をステート管理し,画面(window)サイズが変化するたびに再計算する処理を加えたのと,gridが変化するたびにゲスト写真のポジションを再度割り当て直す処理を追加します.
// pages/spread.js import useWindowDimensions from '../hooks/useWindowDimensions' import shuffle from '../utils/distance_ord' const Spread = ({ initialGuests }) => { // ... // windowサイズをウォッチしてgridを再計算 useEffect(() => { if (windowDimensions.width) { let newGrid = [] // for each item has width, height = 80px const xMax = windowDimensions.width / UNIT_OF_GRID const yMax = windowDimensions.height / UNIT_OF_GRID for (let y = 0; y < yMax; y++) { if (y % 2 == 0) { for (let x = 0; x < xMax; x++) { newGrid.push([y/yMax * 100, x/xMax * 100]) } } else { for (let x = 0; x < xMax-1; x++) { newGrid.push([y/yMax * 100, (x+0.5)/xMax * 100 ]) } } } // 画面中心の一定のエリアは除外した newGrid = newGrid.filter(grid => !(25 < grid[1] && grid[1] < 78 && 33 < grid[0] && grid[0] < 65)) // shuffleはgridを中心からの距離(の2乗)でソートする関数 setGrid(shuffle(newGrid)) } }, [windowDimensions]) // gridをウォッチしてゲストの配置座標を振り直す useEffect(() => { const postGuests = guests.map((guest, index) => { const n = grid.length const top = n === 0 ? 0 : grid[index % n][0] const left = n === 0 ? 0 : grid[index % n][1] return { ...guest, styleProps: { top: `${top}%`, left: `${left}%`, }, render: true, } }) setGuests(postGuests) }, [grid])
windowサイズが変化するたびに座標を再計算しソートするには O(n) + O(nlogn) の計算がクライアント側で必要ですが,イベントの参加者は1000人もこないですし,n < 1000 を前提に作れたので,現実的な処理時間になりそうです.
要件3番外編:集合体恐怖症の方も気分を害さないように
さて,ここまで実装してみて,途中経過をSlackで運営メンバーに共有してみると...
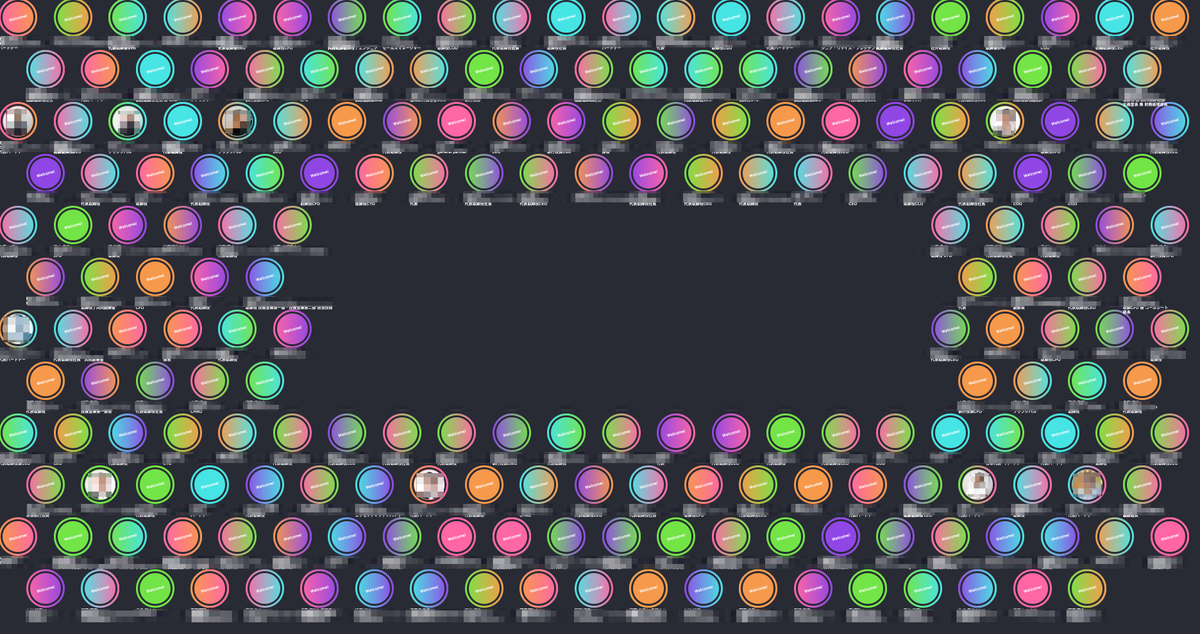
スタンプが1個もつかない...! むしろ「気持ち悪い」という趣旨のコメントが...

たしかに,ギョッとする見た目なんですよね.テストデータは写真素材が少なかったので,デフォルトにした蛍光カラーのアバターが目立つとはいえ.
「気持ち悪い」という趣旨のコメント,冗談めかして言われてますがクリティカルな問題だと認識しました.当日大きなスクリーンに映るこの画面を見て同じ気分になるゲストがいるかもしれない,と.
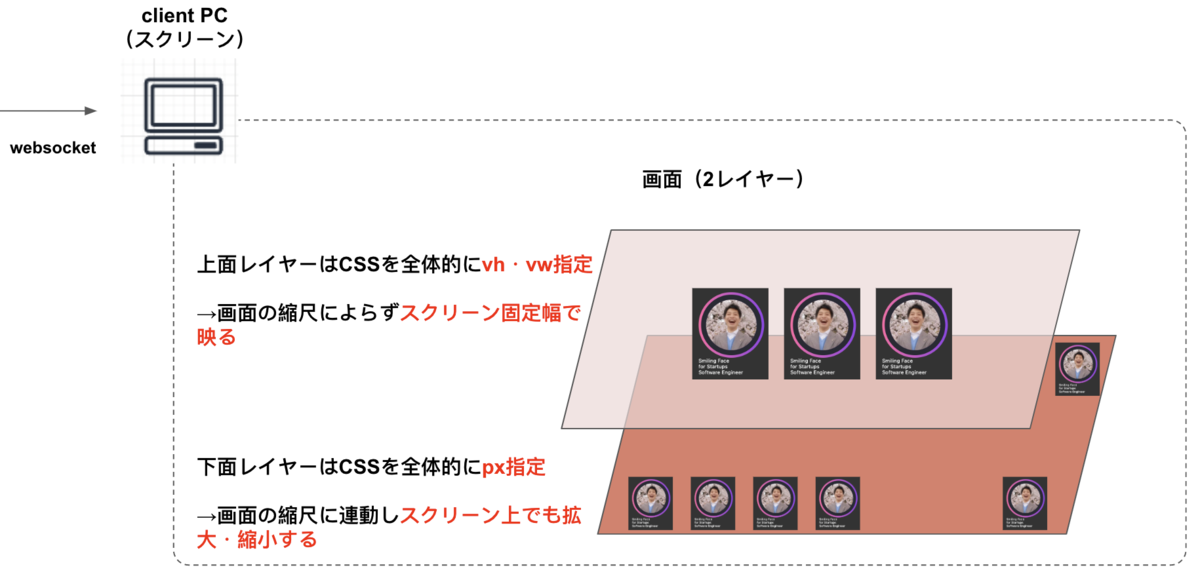
そこで,画面の縮尺を変化させて,集合体っぽく映らないように対応できるようにしておきました.つまり,
- 画面全体にわたって整列しない程度にまで縮小する
- 画面内に20個くらいしか映らない程度まで拡大する
といった操作を当日行えるようにしておきました.

ただし,どのような縮尺だったとしても画面中央に出てくる新たなゲストは大きく映したかったので,これらの要素は全てCSS属性を vhや vw で指定し,他は px指定するように変更しました.

要件4:背景は感謝祭の画像を検討
実装者としてはもっとも簡単なこの部分の実装が,一番ユーザーの印象にインパクトを与えるんですよね.
背景を変えて,ついでにちょっとしたアニメーションも追加します.

さて,開催数日前にここまでの状態に仕上がり,運営メンバーがいるチャネルに連絡してみると...
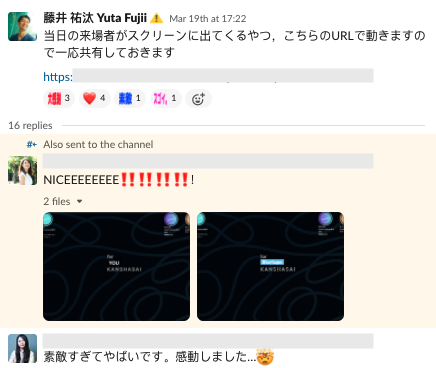
上出来!この反応を見た時に,「これなら当日出してもゲストが見てくれそう」と直感しました.
そのほか
一時のプロジェクトでAWSリソースを変に汚したくなかったので,終わったら全てもれなく削除が可能なようにIaC(Terraform)管理しておきました.デプロイについてはGithub Actionsでdocker-composeファイルを元にECS serviceを起動するようにしています.
こうして完成したアプリケーションは,会場受付においてあるスプレッドシートと連動して次のように動きます.
完成

感謝祭当日
幸いなことに何の問題もなく,きちんと動きました.

また,ありがたいことにSNSへの投稿素材にしてくださった方もいらっしゃいました.
フォースタ感謝祭行ってきました。久方ぶりの人たくさん会えてよかったです! pic.twitter.com/qgSDJFoKi6
— Yabebe / ZERO to THREE 2022 (@yabebe_t) March 23, 2022
エンジニアとして大変うれしいですね.
おわりに
社内から複数のフィードバック聞かせていただき,目的だった「ゲスト同士の交流を促進」に多少なり貢献できていたようです.よかった.
一方で,「もう帰ったのかわからない」「フォースタ社員がより交流を促進できるためにはxxといった使い方ができたらよかった」など次の課題も見えました. 次回やるなら改善してみたいところです.
We are Hiring!
 フォースタートアップスでは共に働く仲間を募集中です。本記事を読んで興味を持っていただけましたら採用情報をご覧ください。
フォースタートアップスでは共に働く仲間を募集中です。本記事を読んで興味を持っていただけましたら採用情報をご覧ください。