はじめに
こんにちは、エンジニアインターン生の光岡です。
STARTUP DBのエンジニアをしています。
今回は、STARTUP DBでElasticsearch Aggregationsを使用したファセット検索数の取得を実装したので詳細を書いていこうと思います。
Elasticsearchとは
Elasticsearchとは、分散型で無料かつオープンな検索・分析エンジンです。*1
スケーラビリティと高可用性に優れているため、多くのサービスで検索システム、ログ分析などに活用されています。
STARTUP DBも企業等の検索機能にElasticsearchを使用しています。
13,000社以上の企業検索の高速化を実現するため、日々改良を加えながら活用しています。
STARTUP DBが抱えていた課題
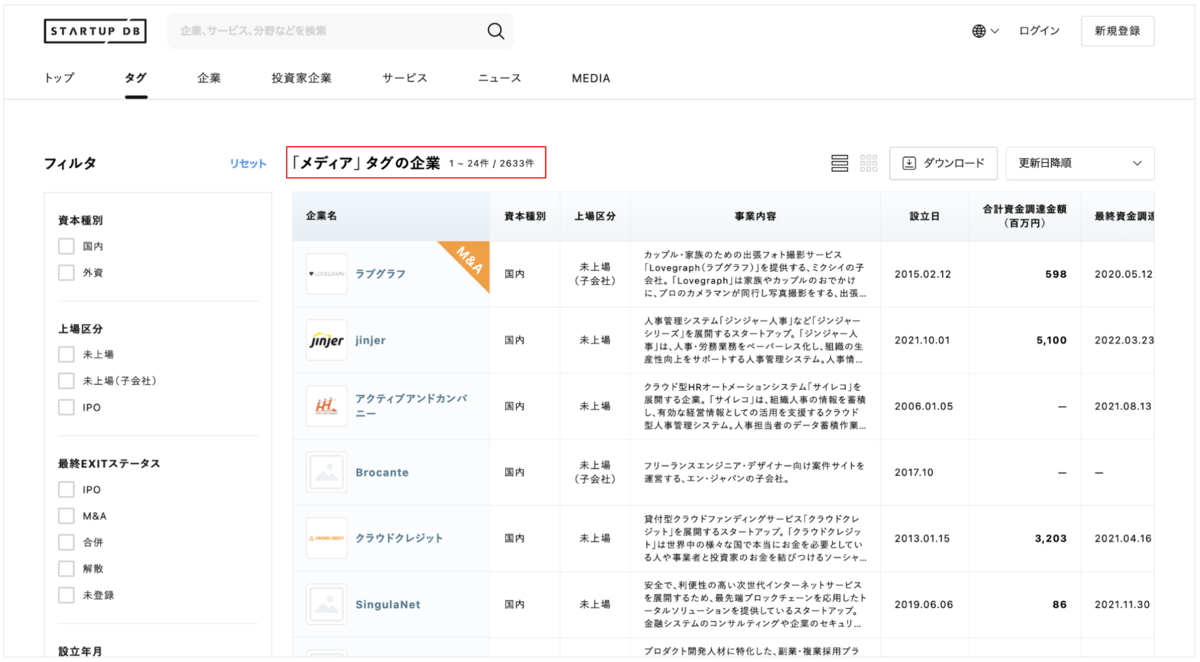
STARTUP DBではファセット検索を設置しユーザーに検索の切り口を提示しています。検索タグごとにコンテンツである企業数を表示していますが、この数値の更新を行うバッチ処理の負荷が高いという課題がありました。
ファセット検索とは
ファセット検索(ファセットナビゲーション)とは、サイトのナビゲーションの種類を指す用語です。
ユーザーに検索条件を入力させるのではなく、あらかじめユーザーに使いやすいであろう検索条件をサイト側が用意しておき、ユーザーはそれを選ぶだけでコンテンツを絞り込んでいけるような仕組みのことを指します。*2
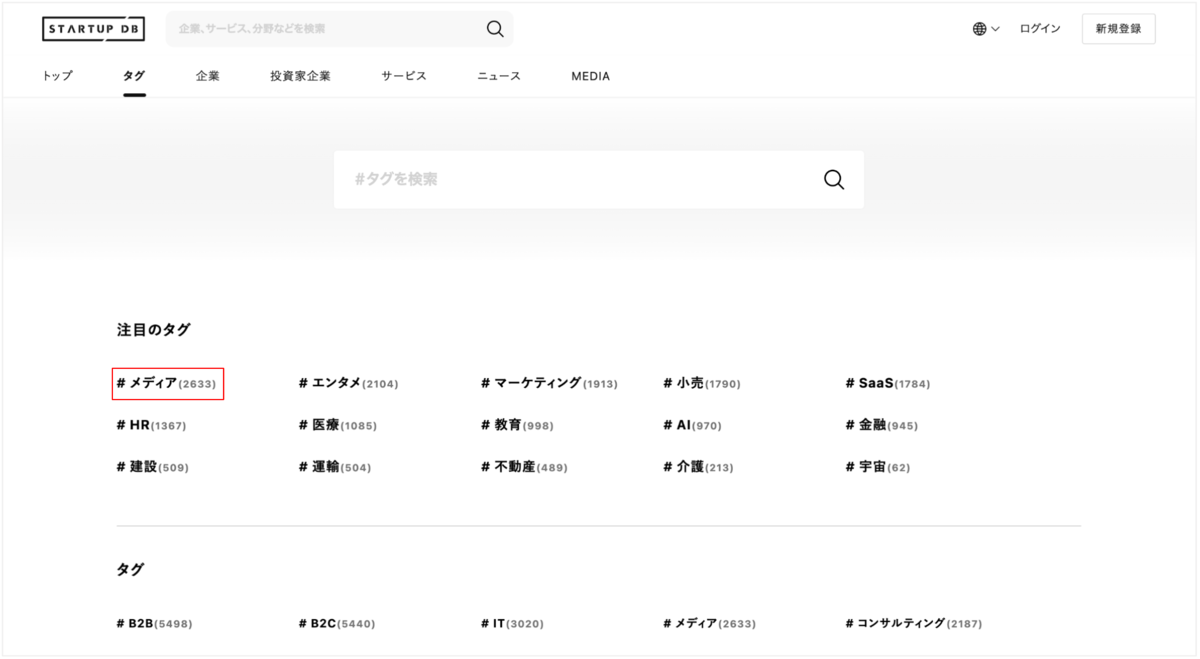
またSTARTUP DBでは、各タグの右側に、そのタグの検索でヒットする企業数を表示しています。
* タグ一覧ページ
更新処理とパフォーマンスの問題
今まではタグを起点にした検索で企業数を取得していました。
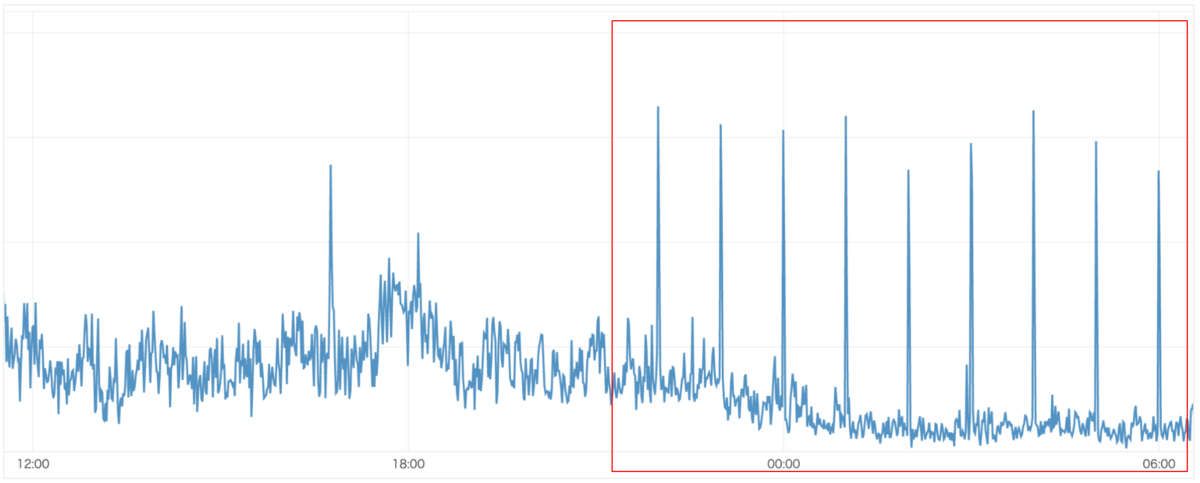
しかし、タグの個数分Elasticsearchにクエリを発行するためパフォーマンスがよくありません。また、企業数の取得は1時間に1回のバッチ処理を利用して更新していたため、そのタイミングだけ繰り返しリクエスト数が上昇していました。
下記グラフは深夜時のリクエスト数のため、バッチ処理以外のリクエスト数は少ないですが、日中はリクエスト数が増加し、リクエスト数が多いことによるエラーが数件発生してしまい、急いで対応する必要のある課題でした。
解決策
STARTUP DBが検索で利用しているElasticsearchにはAggregationsという、ある特定の条件に基づく集計結果を1つの応答にまとめて返す機能があります。
今回はこのAggregationsを利用することで、タグに紐付く企業数を1回のリクエストで取得できるよう改善します。
Aggregationsとは
ElasticsearchにはAggregationsという機能があり、データの統計情報をグループ化したり展開したりすることができます。検索を実行すると同時に、その検索によるヒットの結果とは別に、集約された結果を1つの応答にまとめて返すことができます。SQLの場合、GROUP BYと同等の機能になります。
公式ドキュメントに掲載されている例として、米国口座の位置情報を保持したElasticsearchに対して、全ての口座を州ごとにグループ化して、下記のような1回のレスポンスに全ての結果を返すことができます。*3
{
"took": 29,
“timed_out”: false,
“_shards”: {
“total”: 5,
“successful”: 5,
“failed”: 0
},
“hits” : {
“total” : 1000,
“max_score” : 0.0,
“hits” : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 20,
"sum_other_doc_count" : 770,
"buckets" : [{
"key" : "ID", # アイダホ州
"doc_count" : 27
}, {
"key" : "TX", # テキサス州
"doc_count" : 27
}, {
"key" : "AL", # アラバマ州
"doc_count" : 25
}, {
"key" : "MD",
"doc_count" : 25
}, {
"key" : "TN",
"doc_count" : 23
}, {
"key" : "MA",
"doc_count" : 21
}, {
"key" : "NC",
"doc_count" : 21
}, {
"key" : "ND",
"doc_count" : 21
}, {
"key" : "ME",
"doc_count" : 20
}, {
"key" : "MO",
"doc_count" : 20
},]
}
}
}
また、Aggregationsには合計や平均などを計算して出力するMetric、他の集計結果から入力を得るPipeline、フィールド値や範囲の基準に基いてグループ化するBucketの3つの集計のカテゴリーが存在します。*4
今回の実装ではフィールド値にタグ名を指定してグループ化する必要があるため、Bucketを使用します。
実装
今回の実装では、各タグに紐付く企業数を1回のリクエストで取得していきます。 Aggregationsを用いたクエリを作成し、レスポンスを確認してみます。
クエリ作成
先ほど述べたBucketによる集計を行うため、Terms aggregationによるfield指定で、タグ名毎にbucketを作成して集計していきます。
また、企業情報を持つドキュメントは一部ネストした状態でデータを保持しています。今回対象のタグもネストして保存しているため、Nested aggregationを参考にして企業数を集計するクエリを作成します。
* 企業情報のドキュメント構成(mapping)
"mappings" : {
"dynamic" : "false",
"properties" : {
"id" : { # 企業ID
"type" : "integer"
},
“name”: { # 企業名
“type” : “keyword”
},
“tags” : { # タグ情報
“type” : “nested”
“properties” : {
“id” : { # タグID
“type” : “integer”
},
“name” : { # タグ名
“type” : “text”
“analyzer” : “synonym_keyword_analyzer”
},
“slug” : { # タグのslug
“type” : “keyword”
}
}
}
}
}
企業のID、名前などの情報の他に、タグのID、名前、slugをネストさせて構成しています。
タグ毎に集計する際、tag.slugをfieldに指定しグループ分けします。
* 企業数を集計するクエリ
aggs : {
“tags” : {
“nested” : {
“path” : “tags”
},
“aggs” : {
“tag_slug” : {
“terms” : {
“field” : “tags.slug”,
“min_doc_count” : 0,
“size” : 10000
}
}
}
}
}
実装上の工夫
クエリ作成時に、ネストしたaggs内でsize指定を行わないと、企業数がタグ10件分しか返ってきませんでした。
原因は、既存のクエリで設定している、ある条件による検索のヒット数に対するsize指定が、ネストしたaggs内での集計結果数には反映されないことでした。そのため、sizeの指定が無い場合、Elasticsearchはデフォルトで10件のみを返します。 今回は、Elasticsearchで設定でき得る最大値の10000を指定して対応しています。
レスポンス
上記のクエリを使用することで、buckets内に ”key”, “doc_count” の組み合わせで、各タグに紐付く企業数の一覧を取得することができます。
{
.
.
“aggregations” : {
“tags” : {
“doc_count” : 100,
“tag_slug” : {
“doc_count_error_upper_bound” : 0,
“sum_other_doc_count” : 0,
“buckets” : [
{
“key” : "b2c",
“doc_count” : 10
},{
“key” : "b2b",
“doc_count” : 9
},{
“key” : "media",
“doc_count” : 8
},{
“key” : "finance",
“doc_count” : 7
},{
“key” : "entertainment",
“doc_count” : 6
},{
“key” : "hr",
“doc_count” : 5
},
.
.
.
]
}
}
}
}
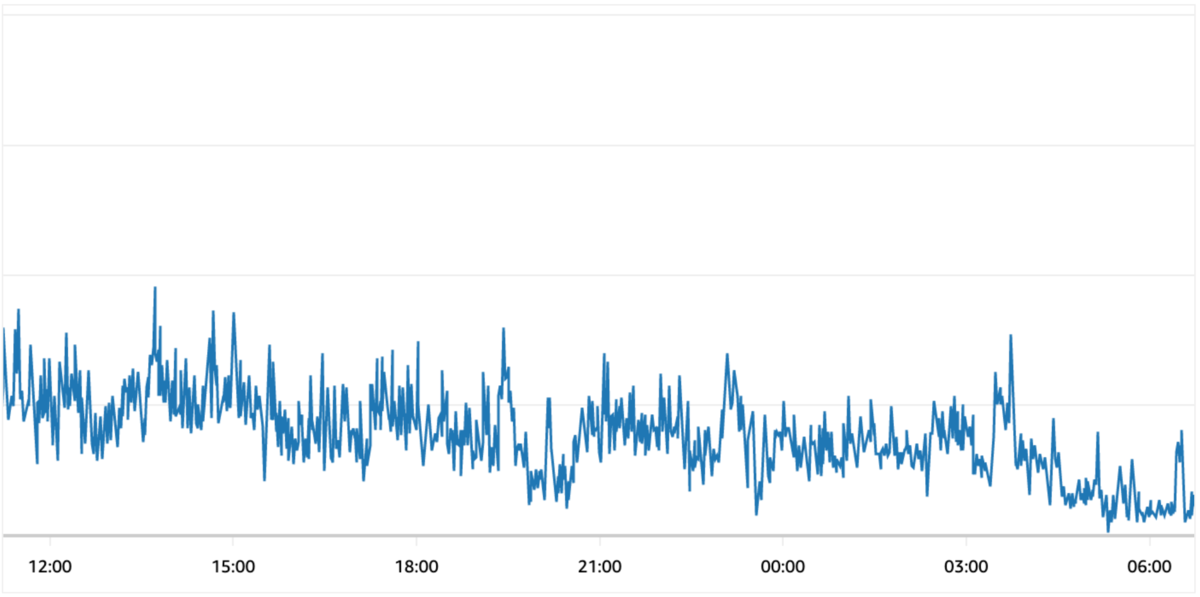
バッチ処理では、このレスポンスを基に各タグの企業数をTagsテーブルに保存しています。
実装前はタグの個数分Elasticsearchにリクエストを送ってしまいましたが、1回のリクエストで取得することができました。
実装を終えて
1回のリクエストで全てのタグに紐付く企業数を取得できるようになったことで、負荷を下げ、安定したパフォーマンスでElasticsearchを稼働させることができるようになりました。 その結果、バッチ処理の更新期間を短くすることで、STARTUP DB専任リサーチャーが取得してきた企業情報をよりタイムリーに反映することが可能になりました。
STARTUP DBはSTANDARDプランを先月開始し、日々アップデートしています。より最新の情報をお届けできるよう引き続き開発に取り組んでいきます。