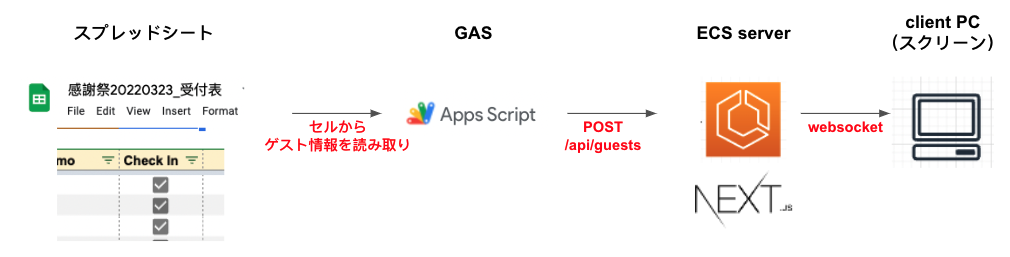
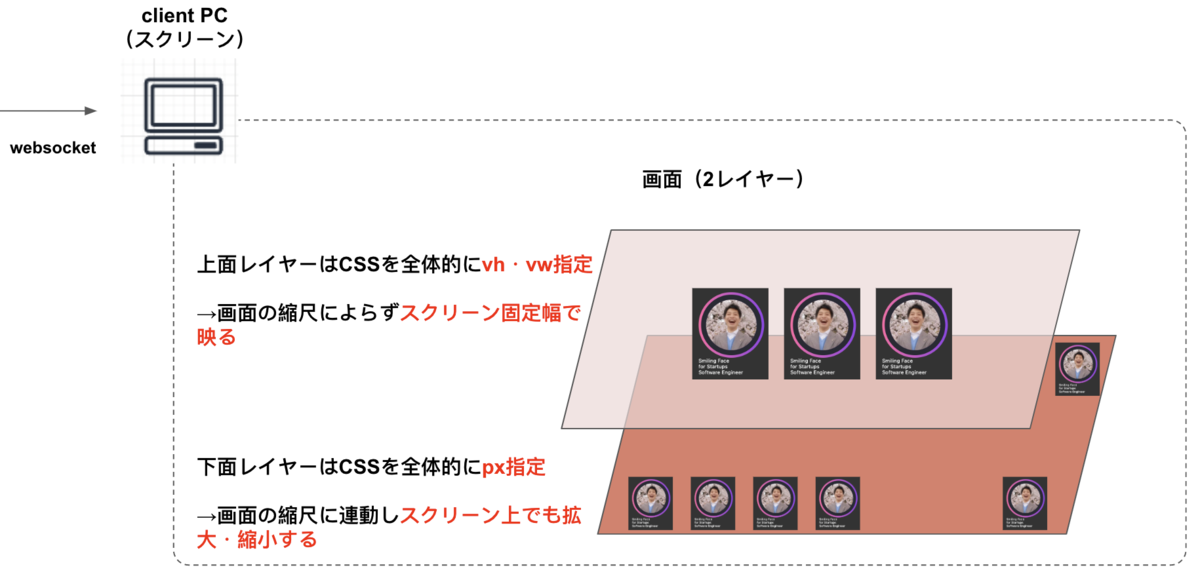
初めまして、杉谷です。
初めまして、杉谷です。
2021/10月から入社までの約5ヶ月間、インターンとして働き4月から正社員として入社しました。 今回は、そのインターンについてや5ヶ月間で学んだことについて書いていきたいと思います。
フォースタのインターンってどんなことするの?
最初に、インターン内容についてですが、 インターンは、大きく「課題」・「実務」の2ステップ構成になっています。
まず初めに、課題に取り組みます。

この課題は、実務で扱うプロダクト内容や扱う技術への理解を深める為に設けられています。 例を挙げると、弊社ではElasticsearchという検索エンジンを使っているので、課題では「実際にフィールドを追加してAPIのレスポンスを返す」といった実務でも行われるAPIの改修に取り組んでもらったりしています。 フォースタ以外でも通用する技術を効率よくキャッチアップ出来る機会なので、1つの魅力的な点かなと個人的には思っています。 課題を修了することで、一定レベルのプロダクト・技術的な知識を共有した状態になり、スムーズに実務に着手することが出来ます。
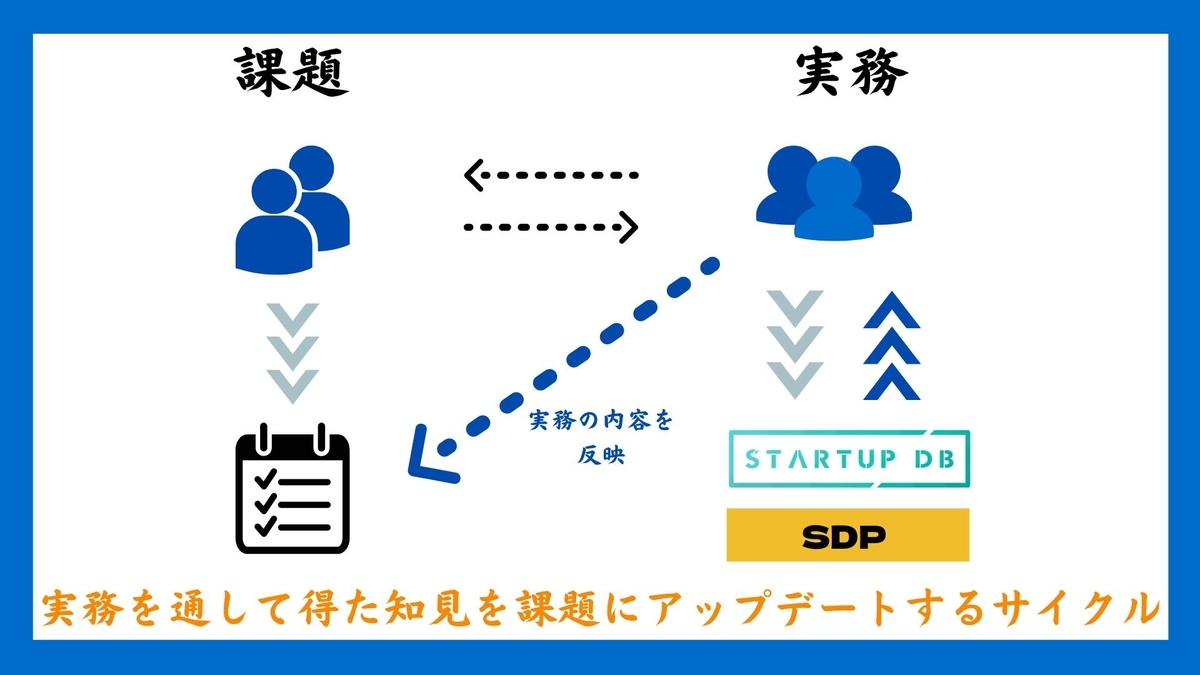
またこれはユニークな点ですが、課題はインターン生自身の手によって常に更新されています。 更新というのは具体的に、課題を修了し実務に携わっているインターン生が、前もって学んでおいた方が良いことをまとめ、それを課題に反映させています。彼らが主体性を持って自身の学びを課題にアウトプットすることで、常に課題は改善され、同時に彼ら自身の成長にも繋がるというサイクルです。 実際、私が課題に着手していた際は課題の数は6つでしたが、現在では11個に増えています。ただ多ければ良いという話でもないので、初期に追加された課題を複数まとめてアップデートし、より密度の高い課題にすべくインターン生の方々が自身の経験をもとに試行錯誤しています。(課題10くらいまでに抑えるのが理想です)
そんな優秀なインターン生が寄稿している記事もありますので是非ご一読下さい。
課題を修了すると、いよいよ実務に取り組みます。 主にインターン生は、『STARTUP DB』やその裏側にあたる管理システム(STARTUPS DATA PLATFORM)に携わります。 社内にいるユーザーからの意見を基に改修を行なったり、新規機能開発を行うなど幅広いタスクに着手しています。 またタイトルにある通り、社員とインターンの間に垣根がなく、実務に当たる際は優先的なタスクから順にインターン生・正社員問わず着手しています。
さらに、自身の興味のあるプロダクトや磨きたい技術が実務にあれば、手を挙げて挑戦できます。 私自身、インターンとして働いている時にフロントエンドの開発に興味があったので、手を挙げた結果翌月からフロントの開発にもアサインされました。(他にもインフラをやりたくて手を挙げて、現在terraformをバリバリかいているインターン生もいます) 社員との垣根が無く自由度が高い分、それに伴う責任やプレッシャーもありますが、やりたいことに挑戦できる環境はとても貴重な為、モチベーション高く業務にコミット出来る環境だなとインターンを通して感じています。
スキルアップ会や勉強会で幅広い知識をインプット
エンジニアインターン生は、業務時間内で課題や実務以外に2つの会に参加しています。
スキルアップ会(輪読会)では、主に1冊の本をみんなで輪読しディスカッションを行いスキルアップを図っています。その一冊は、社員・インターン生関係なくビブリオバトルを通して選ばれます。 詳しい内容は下記の記事にて紹介していますのでご参照下さい。
勉強会では、発表者を募りそれぞれが興味のあることや共有したいことをテーマにして30分プレゼンしています。 テーマは様々で、実務に即したものから自身の興味のあることについてなど話しています。 もちろん、インターン生も発表することが可能で、自身の学んだことをアウトプットする場所として推奨されています。 私自身もこの記事を書く前に、勉強会でこれまで学んできたことについて発表し、改めてこの5ヶ月で学んできたことを自分の中により深く落とし込むことが出来ました。
この他にスプリント定例や各種mtgもあるのですが、それはまた別の記事で書ければなと思っています。上記の内容でもっと詳しく知りたいと思った方は、ぜひ一度カジュアル面談に来て頂けると嬉しいです。
インターンを通して学んだこと
ここからは自身がインターンを通して学んだことについて書いていきたいと思います。 細かいところまで列挙してしまうと、長くなってしまうので特に自身への影響が大きかったものを挙げたいと思います。

理解しやすくパフォーマンスを考慮したコードを書けているか
これは、自身のコードが他人にとって可読性が高いか、プロダクトにどれくらいの負荷がかかるのかといった点を考慮しながら書けているか常に意識すべきであるという学びを表しています。
フォースタのインターンでは、エラー調査や改修作業などは主にインターン生が担当しています。 エラー調査はプロダクトを知るのにとても良い方法で、色々な箇所のソースコードを読み漁ります。そうして改修箇所を特定しリファクタリングを行うのですが、当然調査をすればするほどプロダクトのソースコードに詳しくなっていきます。そうなると、「あの箇所、ページの描画速度が遅いから改善したほうがいいな」とか「ここら辺は共通化できそうだ」という点が出てきます。 そうして改修を重ねるうちに、自身が書くソースコードでもパフォーマンスを考慮して書けているかを自然と意識するようになりました。 これは、実務に入らないと分からないことだなとインターンを通して深く理解しました。
自走できないと活躍できない
今まで「自走力」というのは、ある一定の技術力を有することであると考えていました。 しかしそれ以外にも「目標を持って取り組み、それに見合った行動・成果を出す」といったことも「自走力」であるとインターンを通して学びました。
これを実感したのは、実務に取り掛かった初期の頃です。 課題を通してプロダクトへの理解は一定程度得たものの、いざタスクに取り掛かろうとすると何から着手すべきかの順序立てが上手く出来ませんでした。結果、当初予定していたよりもだいぶかかってしまうという結果に終わりました。
そこから、「まずはタスクをしっかり期日までに完了させる」という目標を持つようになりました。 そのような目標を持つことで、段階的にやるべきことを順序立てていけるようになりました。 また、質問の仕方も目標を持ったことで徐々に変わっていきました。質問も同じように順序立て、具体的にどうしたかったのか、それが出来ない理由と試したことは何かなどを落とし込んで質問を行えるようになりました。 そうすることで煮詰まることが少なくなり、タスクをこなすスピードが改善され目標に対して自身の行動や成果が追いつくようになりました。
この学びは、自由度が高いからこそ高い自走力を求められる、フォースタのエンジニアインターンの環境があったからだと実感しています。
ユーザーの領域に関する知識も深く蓄えないとvisionは遠退く
これは、どんな領域・分野のユーザーが『STARTUP DB』をどのように活用し、どのような情報を求めているのか、自分もユーザーのことを深く理解する必要性があるということです。 言い方を変えれば、エンジニアだからと言ってユーザーと接する最前線に行かずにいるのではなく、むしろ前のめりに出て話をしに行き、そこから常にユーザーの本質的な課題を探す姿勢を持つことも重要であるということです。
結局のところ、フォースタのエンジニアが技術力を高めるのはビジョンを達成する為であり、それがモチベーションとなり日々挑戦し続けられます。
私はこの5ヶ月、なるべく自身のプロダクトを使う領域の人や他部署の方と話をするように心がけ、「STARTUP DBが今どんなユーザーに使われているのか」・「STARTUP DBにはどんな情報を求めているのか」といった開発しているだけでは中々見えてこない情報を蓄えるようにしました。そうすることで、ユーザーの視点でプロダクトを見たり、それを基に課題を自分なりに見つけ壁打ちするといったことが出来る様になってきました。そして日々ユーザーと話しその中から見つけ出した課題の解決策をプロダクトに反映させることが、ビジョン実現の一番の近道ではないかとインターンを経て改めて強く実感しています。 またこの学びは、共に目指すべき目標が同じであり挑戦する仲間が集まったフォースタのインターンだったからこそ学べたものと深く実感しています。
ここまで読んで頂きありがとうございます。 この5ヶ月の間、インターンとして挑戦し上記に述べた学びは勿論、それ以外にもたくさんのことを学ぶ貴重な機会でした。 これからは、正社員として日本からグローバルに戦えるスタートアップを創出するべくモチベーション高く挑戦していきたいと思います!