こんにちは、エンジニアの速水です。
フォースタは22年度4Qで社員が115名となりました。その数は毎年130%成長が続き、まさに拡大中の組織です。組織が100人にもなると役割分担ができてくる一方、事業の全体感をパッとつかむのは難しくなってきます。「タレントエージェンシー支援システム(SFA/CRM)」では、スタートアップ企業、転職を希望される人、ポジションの情報を集約しているのですが、組織の拡大に伴いデータ分析を必要とするシーンも増えてきました。 以前からBIツールのRedashを導入していたのですが、運用で出てきた苦しみ、そこからのMetabaseの導入、残る悩みどころについてまとめていきます。
Redash運用で発生した問題
管理できないほどにクエリが増殖した(その数なんと1400以上!)
開発チームへSQLに関するヘルプが増える
ミニマム導入からスタートしたこともあり、Redashはルールがほぼない状態でした。全員が自由にクエリを作成でき、命名規則やタグ管理、アーカイブ基準は曖昧なまま、クエリはどんどん増えていきました。 それに社員が増えることで、下記状態に陥ります。
XXについてデータを出したい!
同じような分析をしているクエリを探すが見つからない!(よくわからん!)
SQLを0から書くのは大変だから、とりあえず開発チームに相談しよう!
開発チームはプロダクト開発の中でデータベースもエンハンスしているので、相談を受けないわけにはいきません。とはいえ、表示項目の順番が異なるだけのクエリや、企業や職種などの絞り込みが若干異なるだけのクエリに、毎度エンジニアの工数をかけるのは苦しくなってきました。データ分析はしてもらいたい、だけどエンジニアが都度個々人の依頼を受けカスタマイズしたSQLを書くのも難しい。 エンジニアがSQL勉強会を開きデータ分析の民主化を図ったりもしましたが、定着は難しく一部の人が習得するのみにとどまりました。
Metabaseで解決できるのか
私はRedash上のクエリ分析を経て「同じデータ元で視点が異なるクエリが並列に保存されていること」を課題と定義しました。
例えば企業の採用支援のシーンにおいて、
企業担当は、自分の担当企業のデータが見たい
マネージャーは、担当チームの企業データが見たい
という状況があります。 データ元は同じなのに、視点(絞り込み、表示項目の有無/順序)の違いによって並列にクエリが増えてしまうと、その見分けは難しくなる一方です。
MetabaseはRedashにないGUIとクエリをディレクトリ管理できることが強みです。
簡単なデータ出力であれば、GUIでクエリを組み立てることができますし、出力におけるカラム(列)の順序変更や、カラムごとの絞り込みがマウス操作でできます。実際に検証環境で何人かに見てもらい、これならSQLを書けない自分でも操作できると感じていただけたのが導入の後押しとなりました。
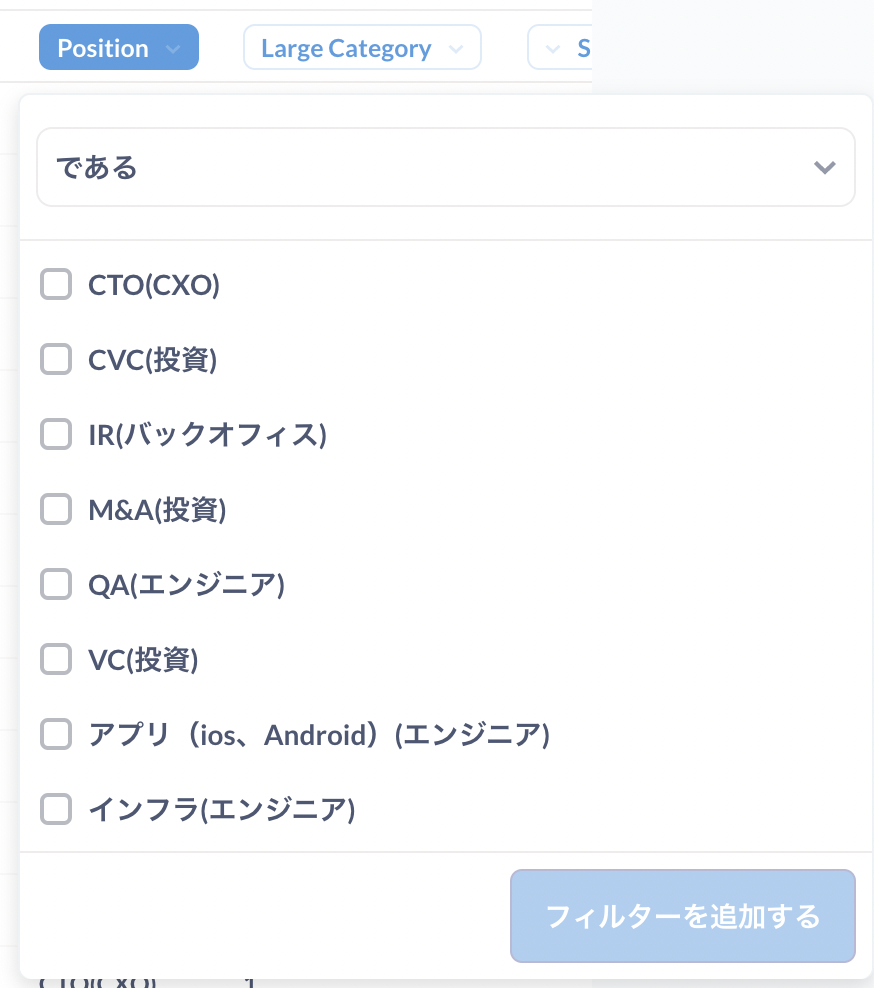
 項目や日付データでの絞り込みがGUIでできるのは純粋に便利
項目や日付データでの絞り込みがGUIでできるのは純粋に便利
またクエリをディレクトリに入れて管理ができるので、分析軸ごとに整理することが可能です。ディレクトリごとにパーミッション(クエリを編集できる、閲覧のみ、閲覧できず)も設定できるので、ユーザグループの作成と合わせて「誰がどこを閲覧/編集できる」を明確にすることができます。
MetabaseはAWS Fargateで手動構築し、Terraformでリソース管理するようにしました。環境を作ってしまえばデータベースと接続するだけなので、短期間で進めることができました。 https://hub.docker.com/r/metabase/metabase
Metabaseで困ったこと
複雑なクエリをRehashから移行しようとすると詰まることが多いです。変数を複数設定したようなクエリは「;」でsyntax errorが出てしまったり。Temporary Tables もサポートされていません。複雑なクエリはSQLをそのままコピーするだけでは動きませんでした。 またGUIで簡単にクエリが作成できる反面、多数のJOINで出力データがとても大きくなることもあるので注意が必要です。
現状
Redashは継続利用しながらMetabaseを利用し始めた段階で、クエリの移行はもちろん、数が増えた時に混乱しないような整理を、悩みながら進めている最中です。進めていて実感しているのは、ディレクトリでクエリ管理できるようになっただけで、パッと見た時にどんなデータがあるのかわかりやすいということです。移行途中でクエリが少ないからじゃない?というツッコミはあれど、以前よりは直感的に認識できるようになったと思います。
フォースタートアップスでは共に働く仲間を募集中です。本記事を読んで興味を持っていただけましたら採用情報をご覧ください。