
こんにちは。エンジニアの藤井(@yutafujii)です。
社内向けのプロダクト「タレントエージェンシー支援システム(SFA/CRM)」のエンジニアをしています。
当社ではデータ分析を専門に行う人がまだいないので、私たちエンジニアがごく簡単なデータ分析を行う場面があるのですが、それを行うためにPythonでの分析環境を手軽に構築しました。
具体的には、複数のRDBやログデータを対象に、RedashでSQLを書いてデータレイク的状態(あるいはデータウェアハウス的状態)を形成し、Google Colaboratory(以下Colab)を用いてその出力をPythonで分析するという流れを説明します。
データ分析を本格化する前のサービス運用をしているPdM・エンジニア・マーケターや、片手間にPythonで分析したいという人を想定読者とさせていただきます。
モチベーション
一言でいえば「データ分析基盤もないし分析者もいないけどちょっとデータ分析したい」というのがこれを思いついたきっかけです。
私は本業がプロダクト開発でデータ分析をする稼働もあまり割けないという事情もあり、いきなりがっつり構築して運用コストがかかるのは避けたいところでした。というわけでざっと満たすべき制約や要件を挙げると次のようなものになりました。
要件
- Pythonで分析できる
- 分析が属人化しないこと
- 当たり前ですがセキュリティリスクが低いこと
- 運用コスト(労働コスト・費用)が低いこと
なお私が入社したときには既にBIツールとしてRedashを利用している状態でした。
Pythonで分析するだけであればBIツールのSQL結果を自分のPCにダウンロードして、ローカルで立ち上げたJupyter Notebook上で分析するということで良いのですが(もちろんこれもやりました)、分析方法や結果の共有をするために
- GitHubを通して分析コードを共有する
- 共有者のローカルでjupyterを立ち上げる
- データをローカルにダウンロードしてもらい分析する
という複雑なステップを踏む必要があります。また、本番データがローカルPCに蓄積することのセキュリティリスクも気になります。
共有のしやすさという観点からブラウザ上で分析したいなと思いつつ、Jupyter NotebookコンテナをAWSのサーバーで起動させることも考えましたが、そこまで使わないのにメンテナンスも認証もセキュリティ対策も全部自分でやるのは面倒だなと思い、Colabを思いつきました。
初めて知る方のためにも、RedashとColabについて簡単に説明しておきます。
Redashとは

RedashはオープンソースのBIツールです。弊社ではEC2に載せてRedashサーバーを起動することでブラウザから利用しています(これらの構築手順もHPに載っています:https://redash.io/help/open-source/setup)。
Redashにはざっと以下のような機能があります。
1.認証・認可
→Google OAuthの設定が容易にできる。また権限設定も簡単
2.複数のデータソースと接続
→RDBMS、各種NoSQL、Google Analytics、スプレッドシートなど
3.クエリ結果の保存
→Redashが保有する固有のデータベース(SQLite3)に格納される
4.クエリ結果へアクセスするAPIの発行
5.複数ソースからデータの結合
→クエリ結果を保存するRedashのデータベースに対してSQLを発行することで実現
これらの機能を活用することで、データレイクや、データウェアハウスを形成することができます。クエリを書かずに集計ができないため非エンジニアが使いにくいとか、クエリの説明を付ける場所が小さすぎて出力数字の定義を把握しづらいとか、承認フローなどがないのでSQLが一方的に増えがちなどの課題もありますが、それでもクエリを一元的に発行出来る場所があることは非常に助かっています。
Colabとは

Colabの愛称で利用されているColaboratoryはGoogleが提供しているサービスで、ブラウザでのPython実行環境を提供しています。その特徴は
- 構築作業がゼロ
- GPUへのフリーアクセス
- シェアの容易さ
というもので、今回の要件にどストライクなサービスです。pipにもanacondaにも触れることなくいきなり
import numpy as np import pandas as pd import seaborn as sns from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split
といったコードを書き始めることができます。
Google Driveと同様のアクセス権限・共有設定が可能なので、認証と認可も実装することなく使えます。ソースコードや演算はGoogleのクラウド上で行われますが、利用規約を読む限りそれらがGoogleに利用されるということはなさそうです。もちろんGoogle側の脆弱性があった場合に自分たちのデータもリスクに晒されるわけですが、一旦このリスクは許容しています。
構成
というわけでRedashとColabを組み合わせてできる分析構成は以下の通りになります。
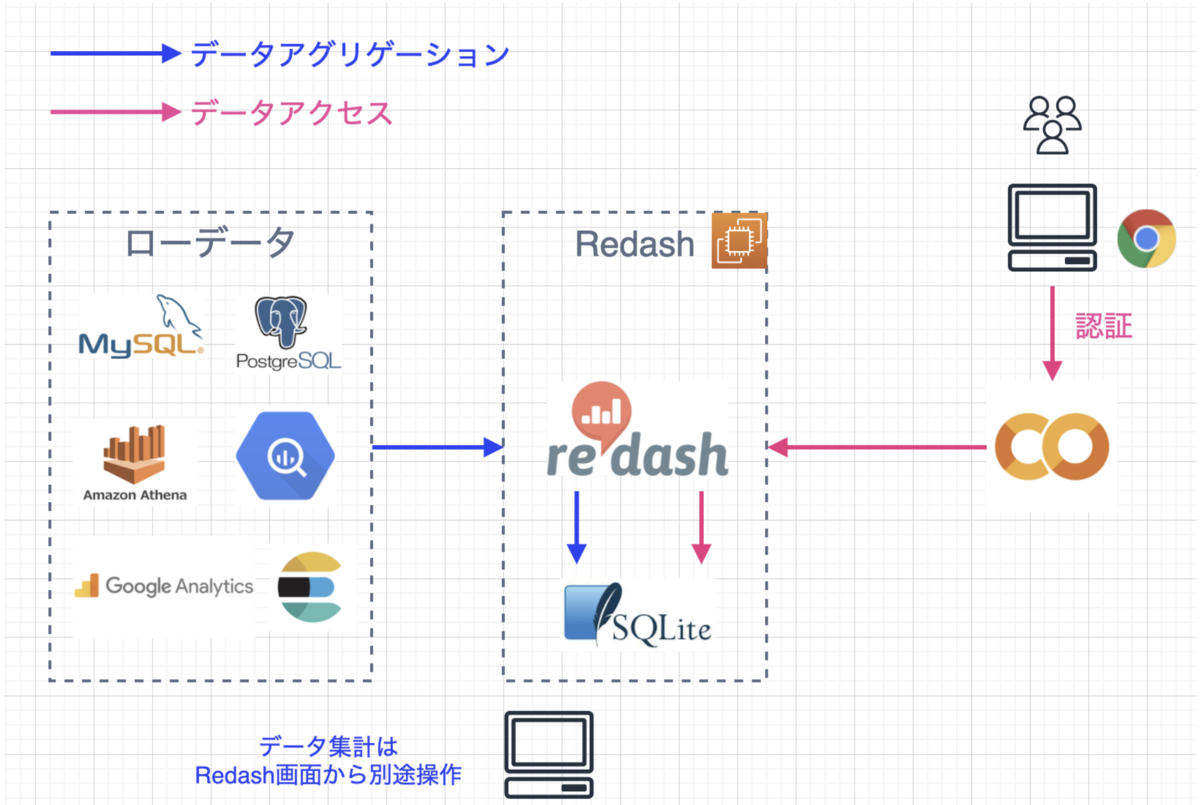
まず、Colabで分析したいデータをRedashで構築しておきます。
Colab側で利用するSQLを作成し
右上の3点リーダーから「Show API Key」を選択
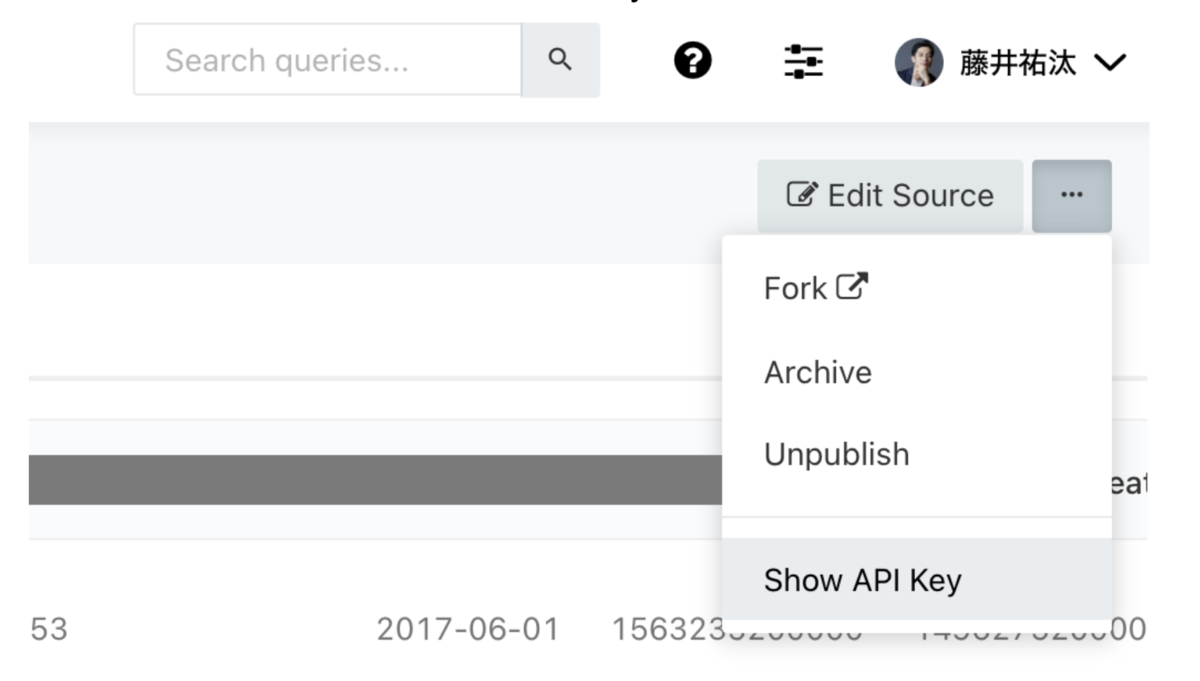
クエリ結果へのアクセスリンクが表示されるのでJSONフォーマットのURLをコピー
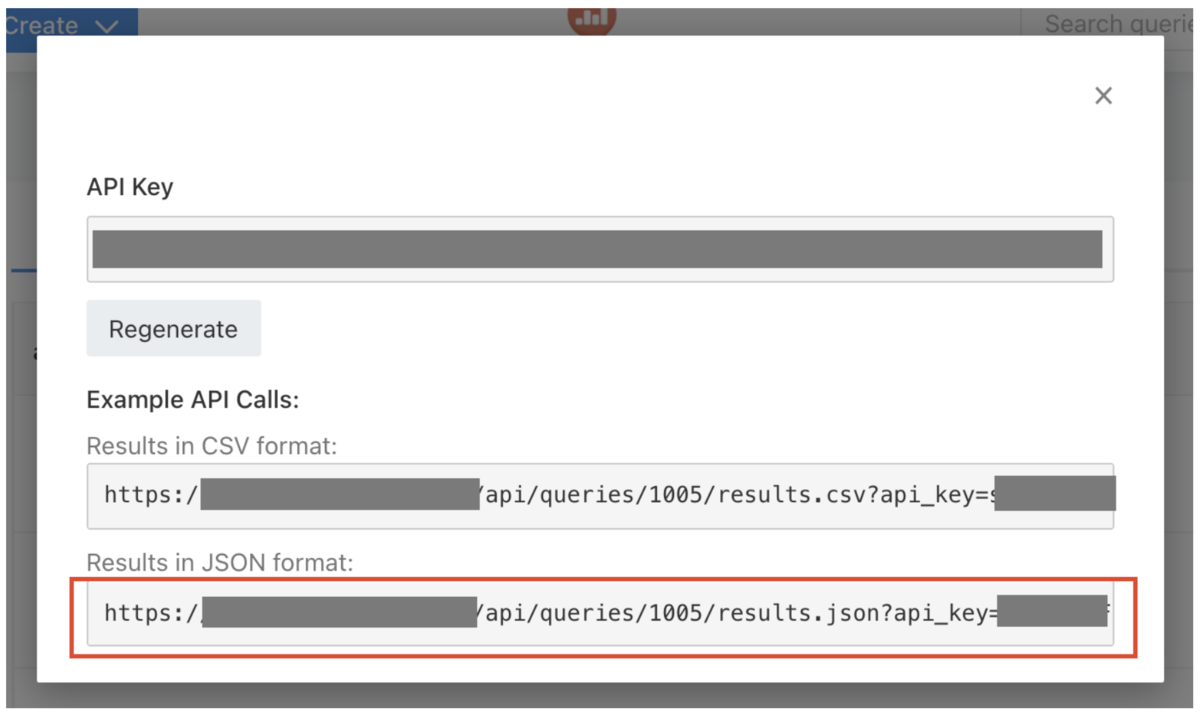
Colabを開いて、あとはコピーしたURLにアクセスするだけです
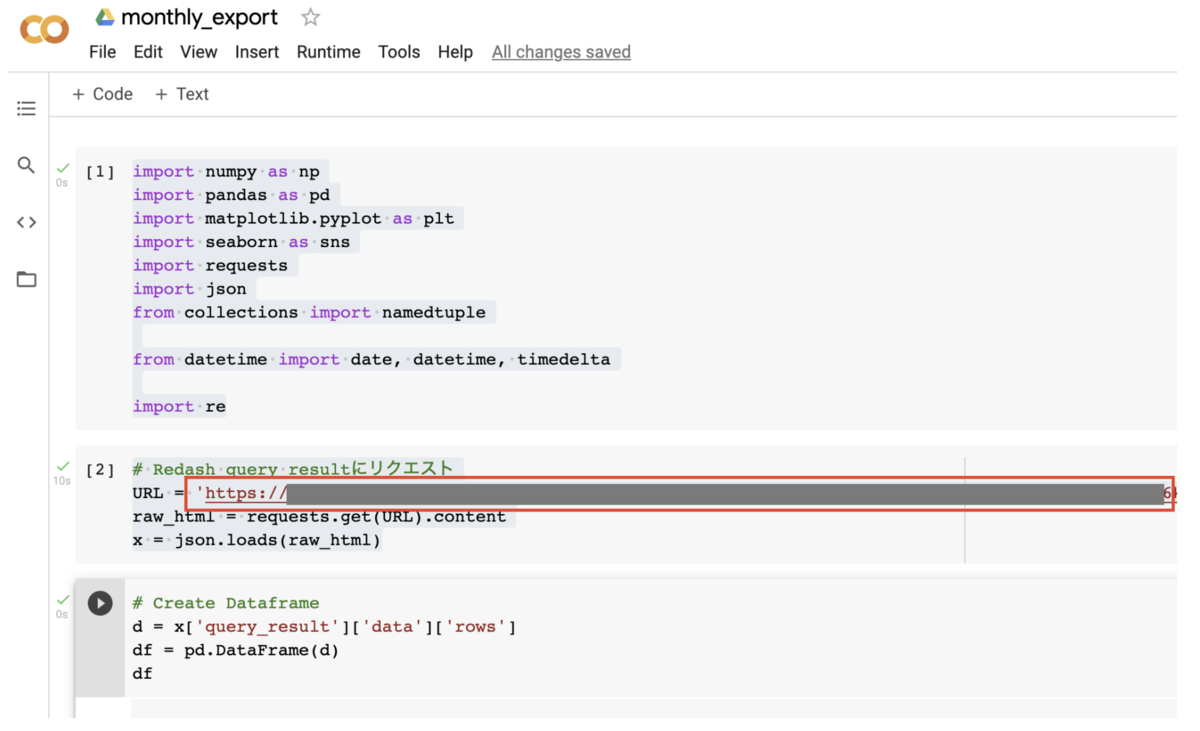
Colabサンプルコード
import numpy as np import pandas as pd import requests import json # Redash query resultにリクエスト URL = 'https://YOUR_REDASH_DOMAIN/api/queries/QUERY_ID/results.json?api_key=XXXXXXXXXXXXXXXXX' raw_html = requests.get(URL).content x = json.loads(raw_html) # Create Dataframe d = x['query_result']['data']['rows'] df = pd.DataFrame(d) df
以上です、構築は非常に簡単ですし、エンジニアでなくてもできるのではと思います。
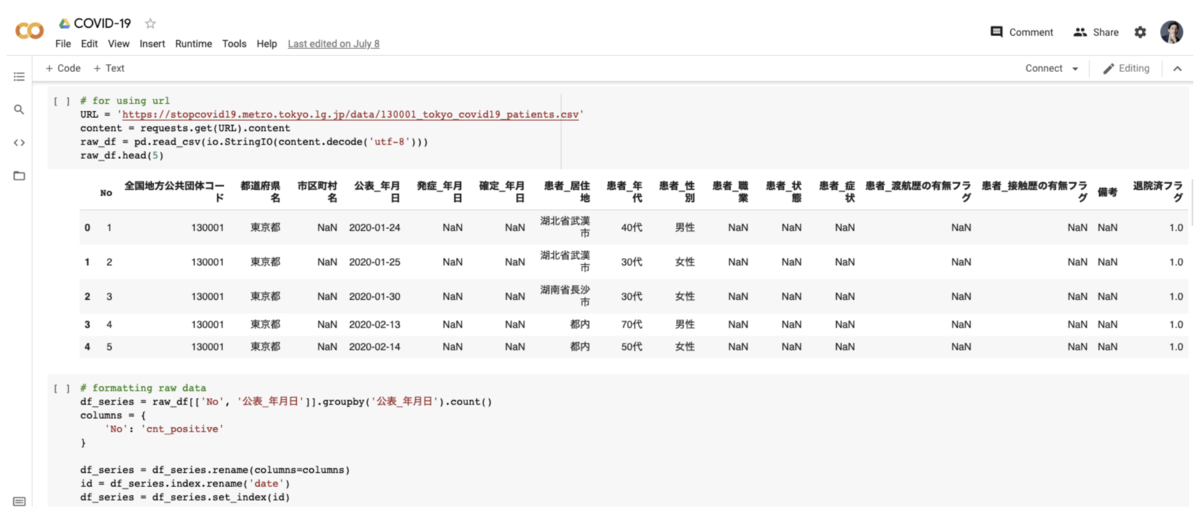
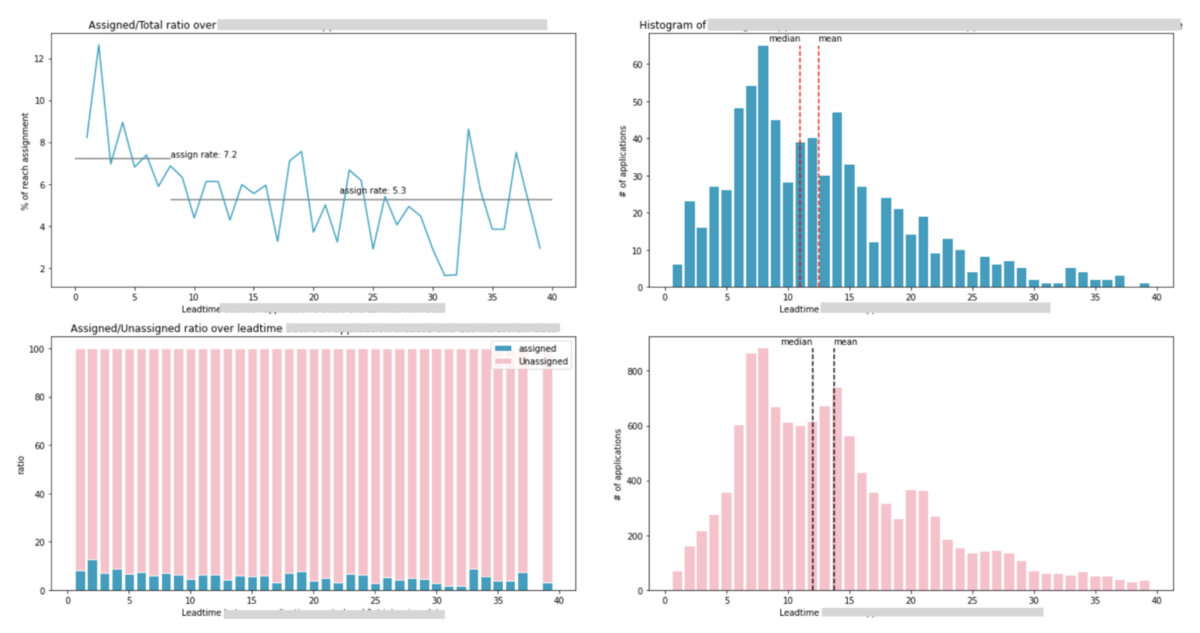
実際に作られたColab上での分析です。快適ですね。SQLでは面倒な集計、細かい設定の可視化や線形回帰などを実際に書いています。
おわりに
冒頭の「モチベーション」で記載した「データ分析基盤もないし分析者もいないけどちょっとデータ分析したい」という目的と制約要件は、Redash + Colabで問題なく充足することができました。
要件
Pythonで分析できる
→ColabでPythonを利用できる
分析が属人化しないこと
→ColabはURLシェアだけで他の人とシェア可能
当たり前ですがセキュリティリスクが低いこと
→認証、サーバー構築を自作せずGoogleにリスクを転嫁
運用コスト(労働コスト・費用)が低いこと
→Colabはフリーで利用可能
構築の手間を考えると非常に便利だと思いつつ、今後はしっかりデータパイプラインを構築してデータレイク・データウェアハウスをきちんと整えていきたいところです。現状ではまだ乱立したローデータと、データレイクとデータウェアハウスが混在したようなRedashクエリ結果しかないため、このあたりを改善してくれる人がいたらぜひお話しさせてください。